Desmitificando la Dimensión Vapnik–Chervonenkis: La Clave para Entender la Complejidad del Modelo y la Generalización en el Aprendizaje Automático. Descubre Cómo la Dimensión VC Moldea los Límites de Lo Que los Algoritmos Pueden Aprender.
- Introducción a la Dimensión Vapnik–Chervonenkis
- Orígenes Históricos y Fundamentos Teóricos
- Definición Formal y Marco Matemático
- Dimensión VC en Clasificación Binaria
- Destrucción, Funciones de Crecimiento y su Significado
- Dimensión VC y Capacidad del Modelo: Implicaciones Prácticas
- Conexiones con el Sobreajuste y los Límites de Generalización
- Dimensión VC en Algoritmos de Aprendizaje Automático del Mundo Real
- Limitaciones y Críticas de la Dimensión VC
- Direcciones Futuras y Problemas Abiertos en la Teoría VC
- Fuentes y Referencias
Introducción a la Dimensión Vapnik–Chervonenkis
La dimensión Vapnik–Chervonenkis (dimensión VC) es un concepto fundamental en la teoría del aprendizaje estadístico, introducido por Vladimir Vapnik y Alexey Chervonenkis a principios de la década de 1970. Proporciona un marco matemático riguroso para cuantificar la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) en términos de su capacidad para clasificar puntos de datos. La dimensión VC se define como el mayor número de puntos que pueden ser destruidos (es decir, clasificados correctamente de todas las formas posibles) por la clase de hipótesis. Este concepto es central para comprender la capacidad de generalización de los algoritmos de aprendizaje, ya que conecta la expresividad de un modelo con su riesgo de sobreajuste.
En términos más formales, si una clase de hipótesis puede destruir un conjunto de n puntos, pero no puede destruir ningún conjunto de n+1 puntos, entonces su dimensión VC es n. Por ejemplo, la clase de clasificadores lineales en un espacio bidimensional tiene una dimensión VC de 3, lo que significa que puede destruir cualquier conjunto de tres puntos, pero no todos los conjuntos de cuatro puntos. Así, la dimensión VC sirve como una medida de la riqueza de una clase de hipótesis, independiente de la distribución de datos específica.
La importancia de la dimensión VC radica en su papel en proporcionar garantías teóricas para los algoritmos de aprendizaje automático. Es un componente clave en la derivación de límites sobre el error de generalización, que es la diferencia entre el error en los datos de entrenamiento y el error esperado en datos no vistos. La célebre desigualdad VC, por ejemplo, relaciona la dimensión VC con la probabilidad de que el riesgo empírico (error en el entrenamiento) se desvíe del riesgo verdadero (error de generalización). Esta relación sustenta el principio de minimización del riesgo estructural, una piedra angular de la teoría moderna del aprendizaje estadístico, que busca equilibrar la complejidad del modelo y el error de entrenamiento para lograr una generalización óptima.
El concepto de dimensión VC ha sido ampliamente adoptado en el análisis de varios algoritmos de aprendizaje, incluidos las máquinas de vectores de soporte, redes neuronales y árboles de decisión. También es fundamental en el desarrollo del marco de aprendizaje Probablemente Aproximadamente Correcto (PAC), que formaliza las condiciones bajo las cuales se espera que un algoritmo de aprendizaje funcione bien. Los fundamentos teóricos proporcionados por la dimensión VC han sido instrumentales en el avance del campo del aprendizaje automático y son reconocidos por instituciones de investigación líderes como el Instituto de Estudios Avanzados y la Asociación para el Avance de la Inteligencia Artificial.
Orígenes Históricos y Fundamentos Teóricos
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, introducido a principios de la década de 1970 por Vladimir Vapnik y Alexey Chervonenkis. Su trabajo pionero surgió del Instituto de Ciencias del Control de la Academia Rusa de Ciencias, donde buscaron formalizar los principios subyacentes al reconocimiento de patrones y al aprendizaje automático. La dimensión VC proporciona un marco matemático riguroso para cuantificar la capacidad de un conjunto de funciones (clase de hipótesis) para ajustarse a los datos, lo cual es crucial para entender la capacidad de generalización de los algoritmos de aprendizaje.
En su núcleo, la dimensión VC mide el mayor número de puntos que pueden ser destruidos (es decir, clasificados correctamente de todas las maneras posibles) por una clase de hipótesis. Si una clase de funciones puede destruir un conjunto de tamaño d pero no d+1, su dimensión VC es d. Este concepto permite a los investigadores analizar la compensación entre la complejidad del modelo y el riesgo de sobreajuste, una preocupación central en el aprendizaje automático. La introducción de la dimensión VC marcó un avance significativo sobre enfoques anteriores, menos formales, a la teoría del aprendizaje, proporcionando un puente entre el rendimiento empírico y las garantías teóricas.
Los fundamentos teóricos de la dimensión VC están estrechamente relacionados con el desarrollo del marco de aprendizaje Probablemente Aproximadamente Correcto (PAC), que formaliza las condiciones bajo las cuales se espera que un algoritmo de aprendizaje funcione bien en datos no vistos. La dimensión VC sirve como un parámetro clave en los teoremas que limitan el error de generalización de los clasificadores, estableciendo que una dimensión VC finita es necesaria para la aprendibilidad en el sentido PAC. Este conocimiento ha tenido un impacto profundo en el diseño y análisis de algoritmos en campos que van desde la visión por computadora hasta el procesamiento del lenguaje natural.
El trabajo de Vapnik y Chervonenkis sentó las bases para el desarrollo de las máquinas de vectores de soporte y otros métodos basados en núcleos, que dependen de los principios de control de capacidad y minimización del riesgo estructural. Sus contribuciones han sido reconocidas por organizaciones científicas líderes, y la dimensión VC sigue siendo un tema central en el currículo de cursos avanzados de aprendizaje automático y estadística en todo el mundo. La Sociedad Matemática Americana y la Asociación para el Avance de la Inteligencia Artificial son solo algunas de las organizaciones que han destacado la importancia de estos avances teóricos en sus publicaciones y conferencias.
Definición Formal y Marco Matemático
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, proporcionando una medida rigurosa de la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) en términos de su capacidad para clasificar puntos de datos. Formalmente, la dimensión VC se define para una clase de funciones indicadoras (o conjuntos) como el mayor número de puntos que pueden ser destruidos por la clase. «Destruir» un conjunto de puntos significa que, para cada posible etiquetado de esos puntos, existe una función en la clase que asigna correctamente esas etiquetas.
Sea H una clase de hipótesis de funciones de valores binarios que mapea desde un espacio de entrada X a {0,1}. Un conjunto de puntos S = {x₁, x₂, …, xₙ} se dice que es destruido por H si, para cada posible subconjunto A de S, existe una función h ∈ H tal que h(x) = 1 si y solo si x ∈ A. La dimensión VC de H, denotada VC(H), es la cardinalidad máxima n tal que existe un conjunto de n puntos en X que es destruido por H. Si se pueden destruir conjuntos finitos de tamaño arbitrariamente grande, la dimensión VC es infinita.
Matemáticamente, la dimensión VC proporciona un puente entre la expresividad de una clase de hipótesis y su capacidad de generalización. Una dimensión VC más alta indica una clase más expresiva, capaz de ajustar patrones más complejos, pero también con un mayor riesgo de sobreajuste. Por el contrario, una dimensión VC más baja sugiere una expresividad limitada y potencialmente una mejor generalización, pero posiblemente a costa de un subajuste. La dimensión VC es central para la derivación de límites de generalización, tales como aquellos formalizados en los teoremas fundamentales de la teoría del aprendizaje estadístico, que relacionan la dimensión VC con la complejidad de la muestra requerida para aprender con una precisión y confianza dadas.
El concepto fue introducido por Vladimir Vapnik y Alexey Chervonenkis en la década de 1970, y es la base del análisis teórico de algoritmos de aprendizaje, incluyendo máquinas de vectores de soporte y marcos de minimización de riesgo empírico. La dimensión VC es ampliamente reconocida y utilizada en el campo del aprendizaje automático y se discute en detalle por organizaciones como el Instituto de Estadística Matemática y la Asociación para el Avance de la Inteligencia Artificial, ambos de los cuales son autoridades líderes en investigación en estadística e inteligencia artificial.
Dimensión VC en Clasificación Binaria
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, particularmente relevante para el análisis de modelos de clasificación binaria. Introducida por Vladimir Vapnik y Alexey Chervonenkis a principios de la década de 1970, la dimensión VC cuantifica la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) midiendo su habilidad para destruir conjuntos finitos de puntos de datos. En el contexto de la clasificación binaria, «destruir» se refiere a la capacidad de un clasificador para etiquetar correctamente todas las posibles asignaciones de etiquetas binarias (0 o 1) a un conjunto dado de puntos.
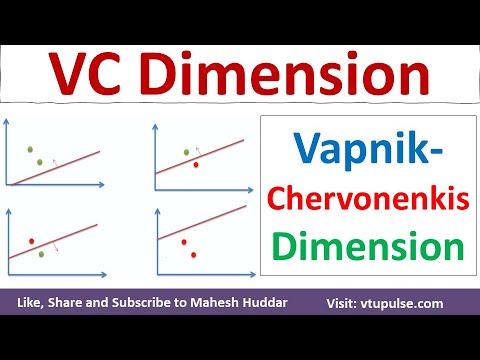
Formalmente, la dimensión VC de una clase de hipótesis es el mayor número de puntos que puede ser destruido por esa clase. Por ejemplo, consideremos la clase de clasificadores lineales (perceptrones) en un espacio bidimensional. Esta clase puede destruir cualquier conjunto de tres puntos en posición general, pero no todos los conjuntos de cuatro puntos. Por lo tanto, la dimensión VC de los clasificadores lineales en dos dimensiones es tres. La dimensión VC proporciona una medida de la expresividad de un modelo: una dimensión VC más alta indica un modelo más flexible que puede ajustarse a patrones más complejos, pero también aumenta el riesgo de sobreajuste.
En la clasificación binaria, la dimensión VC juega un papel crucial en la comprensión de la compensación entre la complejidad del modelo y la generalización. Según la teoría, si la dimensión VC es demasiado alta en relación con el número de muestras de entrenamiento, el modelo puede ajustarse perfectamente a los datos de entrenamiento pero fallar en generalizar a datos no vistos. Por el contrario, un modelo con una dimensión VC baja puede subajustarse, sin lograr capturar patrones importantes en los datos. Así, la dimensión VC proporciona garantías teóricas sobre el error de generalización, como se formaliza en la desigualdad VC y los límites relacionados.
El concepto de dimensión VC es central para el desarrollo de algoritmos de aprendizaje y el análisis de su rendimiento. Sustenta el marco de aprendizaje Probablemente Aproximadamente Correcto (PAC), que caracteriza las condiciones bajo las cuales un algoritmo de aprendizaje puede lograr un bajo error de generalización con alta probabilidad. La dimensión VC también se utiliza en el diseño y análisis de máquinas de vectores de soporte (SVM), una clase ampliamente utilizada de clasificadores binarios, así como en el estudio de redes neuronales y otros modelos de aprendizaje automático.
La importancia de la dimensión VC en la clasificación binaria es reconocida por instituciones y organizaciones de investigación líderes en el campo de la inteligencia artificial y el aprendizaje automático, como la Asociación para el Avance de la Inteligencia Artificial y la Asociación para la Maquinaria de Computación. Estas organizaciones apoyan la investigación y la difusión de conceptos fundamentales como la dimensión VC, que continúan dando forma a los fundamentos teóricos y aplicaciones prácticas del aprendizaje automático.
Destrucción, Funciones de Crecimiento y su Significado
Los conceptos de destrucción y funciones de crecimiento son centrales para entender la dimensión Vapnik–Chervonenkis (VC), una medida fundamental en la teoría del aprendizaje estadístico. La dimensión VC, introducida por Vladimir Vapnik y Alexey Chervonenkis, cuantifica la capacidad de un conjunto de funciones (clase de hipótesis) para ajustarse a los datos y es crucial para analizar la capacidad de generalización de los algoritmos de aprendizaje.
La destrucción se refiere a la habilidad de una clase de hipótesis para clasificar perfectamente todas las etiquetaciones posibles de un conjunto finito de puntos. Formalmente, se dice que un conjunto de puntos es destruido por una clase de hipótesis si, para cada posible asignación de etiquetas binarias a los puntos, existe una función en la clase que separa correctamente los puntos de acuerdo con esas etiquetas. Por ejemplo, en el caso de clasificadores lineales en dos dimensiones, cualquier conjunto de tres puntos no colineales puede ser destruido, pero no todos los conjuntos de cuatro puntos pueden serlo.
La función de crecimiento, también conocida como el coeficiente de destrucción, mide el número máximo de etiquetaciones distintas (dicotomías) que una clase de hipótesis puede realizar sobre cualquier conjunto de n puntos. Si la clase de hipótesis puede destruir cada conjunto de n puntos, la función de crecimiento es igual a 2n. Sin embargo, a medida que n aumenta, la mayoría de las clases de hipótesis alcanzan un punto donde ya no pueden destruir todas las etiquetaciones posibles, y la función de crecimiento aumenta más lentamente. La dimensión VC se define como el mayor entero d tal que la función de crecimiento es igual a 2d; en otras palabras, es el tamaño del mayor conjunto que puede ser destruido por la clase de hipótesis.
Estos conceptos son significativos porque proporcionan una forma rigurosa de analizar la complejidad y el poder expresivo de los modelos de aprendizaje. Una mayor dimensión VC indica un modelo más expresivo, capaz de ajustar patrones más complejos, pero también a un mayor riesgo de sobreajuste. Por el contrario, una dimensión VC baja sugiere una capacidad limitada, lo que puede llevar a subajuste. La dimensión VC está directamente vinculada a los límites de generalización: ayuda a determinar cuántos datos de entrenamiento son necesarios para asegurar que el rendimiento del modelo en datos no vistos será cercano a su rendimiento en el conjunto de entrenamiento. Esta relación se formaliza en teoremas como el teorema fundamental del aprendizaje estadístico, que sustenta gran parte de la teoría moderna del aprendizaje automático.
El estudio de la destrucción y las funciones de crecimiento, y su conexión con la dimensión VC, es fundamental en el trabajo de organizaciones como la Asociación para el Avance de la Inteligencia Artificial y el Instituto de Estadística Matemática, que promueven la investigación y la difusión de avances en la teoría del aprendizaje estadístico y sus aplicaciones.
Dimensión VC y Capacidad del Modelo: Implicaciones Prácticas
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, proporcionando una medida rigurosa de la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) que un modelo de aprendizaje automático puede implementar. En términos prácticos, la dimensión VC cuantifica el mayor número de puntos que pueden ser destruidos (es decir, clasificados correctamente de todas las formas posibles) por el modelo. Esta medida es crucial para entender la compensación entre la capacidad de un modelo para ajustar los datos de entrenamiento y su capacidad para generalizar a datos no vistos.
Una dimensión VC más alta indica una clase de modelos más expresiva, capaz de representar patrones más complejos. Por ejemplo, un clasificador lineal en un espacio bidimensional tiene una dimensión VC de 3, lo que significa que puede destruir cualquier conjunto de tres puntos, pero no todos los conjuntos de cuatro. En contraste, los modelos más complejos, como las redes neuronales con muchos parámetros, pueden tener dimensiones VC mucho mayores, reflejando su mayor capacidad para ajustar conjuntos de datos diversos.
Las implicaciones prácticas de la dimensión VC son más evidentes en el contexto del sobreajuste y el subajuste. Si la dimensión VC de un modelo es mucho mayor que el número de muestras de entrenamiento, el modelo puede sobreajustarse, memorizando los datos de entrenamiento en lugar de aprender patrones generalizables. Por el contrario, si la dimensión VC es demasiado baja, el modelo puede subajustarse, sin capturar la estructura subyacente de los datos. Así, seleccionar un modelo con una dimensión VC apropiada en relación al tamaño del conjunto de datos es esencial para lograr un buen rendimiento de generalización.
La dimensión VC también sustenta garantías teóricas en la teoría del aprendizaje, como el marco de aprendizaje Probablemente Aproximadamente Correcto (PAC). Proporciona límites en el número de muestras de entrenamiento requeridas para garantizar que el riesgo empírico (error en el conjunto de entrenamiento) esté cerca del riesgo verdadero (error esperado en datos nuevos). Estos resultados guían a los prácticos en la estimación de la complejidad de muestra necesaria para un aprendizaje confiable, especialmente en aplicaciones de alto riesgo como el diagnóstico médico o sistemas autónomos.
En la práctica, aunque la dimensión VC exacta es a menudo difícil de calcular para modelos complejos, su papel conceptual informa el diseño y la selección de algoritmos. Las técnicas de regularización, los criterios de selección de modelos y las estrategias de validación cruzada se ven todas influenciadas por los principios subyacentes del control de capacidad articulados por la dimensión VC. El concepto fue introducido por Vladimir Vapnik y Alexey Chervonenkis, cuyos trabajos sentaron la base para la teoría moderna del aprendizaje estadístico y continúan influyendo en la investigación y las aplicaciones en el aprendizaje automático (Instituto de Estadística Matemática).
Conexiones con el Sobreajuste y los Límites de Generalización
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, que influye directamente en nuestra comprensión del sobreajuste y la generalización en modelos de aprendizaje automático. La dimensión VC cuantifica la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) al medir el mayor conjunto de puntos que pueden ser destruidos, es decir, clasificados correctamente de todas las maneras posibles, por las funciones en la clase. Esta medida es crucial para analizar qué tan bien un modelo entrenado en un conjunto de datos finito se espera que funcione en datos no vistos, una propiedad conocida como generalización.
El sobreajuste ocurre cuando un modelo aprende no solo los patrones subyacentes sino también el ruido en los datos de entrenamiento, lo que resulta en un rendimiento deficiente en nuevos datos no vistos. La dimensión VC proporciona un marco teórico para entender y mitigar el sobreajuste. Si la dimensión VC de una clase de hipótesis es mucho mayor que el número de muestras de entrenamiento, el modelo tiene suficiente capacidad para ajustar el ruido aleatorio, aumentando el riesgo de sobreajuste. Por el contrario, si la dimensión VC es demasiado baja, el modelo puede subajustarse, sin capturar la estructura esencial de los datos.
La relación entre la dimensión VC y la generalización se formaliza a través de límites de generalización. Estos límites, como los derivados del trabajo fundamental de Vladimir Vapnik y Alexey Chervonenkis, establecen que con alta probabilidad, la diferencia entre el riesgo empírico (error en el conjunto de entrenamiento) y el riesgo verdadero (error esperado en nuevos datos) es pequeña si el número de muestras de entrenamiento es suficientemente grande en relación con la dimensión VC. Específicamente, el error de generalización disminuye a medida que aumenta el número de muestras, siempre que la dimensión VC se mantenga fija. Esta visión sustenta el principio de que los modelos más complejos (con mayor dimensión VC) requieren más datos para generalizar bien.
- La dimensión VC es central para la teoría de convergencia uniforme, que asegura que los promedios empíricos convergen a valores esperados uniformemente sobre todas las funciones en la clase de hipótesis. Esta propiedad es esencial para garantizar que minimizar el error en el conjunto de entrenamiento conduzca a un bajo error en datos no vistos.
- El concepto también es integral al desarrollo de la minimización de riesgo estructural, una estrategia que equilibra la complejidad del modelo y el error de entrenamiento para lograr una generalización óptima, como se formaliza en la teoría de máquinas de vectores de soporte y otros algoritmos de aprendizaje.
La importancia de la dimensión VC en la comprensión del sobreajuste y la generalización es reconocida por instituciones de investigación líderes y es fundamental en el currículo de la teoría del aprendizaje estadístico, como lo establecen organizaciones como el Instituto de Estudios Avanzados y la Asociación para el Avance de la Inteligencia Artificial. Estas organizaciones contribuyen al desarrollo continuo y la difusión de avances teóricos en el aprendizaje automático.
Dimensión VC en Algoritmos de Aprendizaje Automático del Mundo Real
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, proporcionando una medida rigurosa de la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) que un algoritmo de aprendizaje automático puede implementar. En el aprendizaje automático del mundo real, la dimensión VC desempeña un papel crucial en la comprensión de la capacidad de generalización de los algoritmos: qué tan bien se espera que funcione un modelo entrenado en una muestra finita en datos no vistos.
En términos prácticos, la dimensión VC ayuda a cuantificar la compensación entre la complejidad del modelo y el riesgo de sobreajuste. Por ejemplo, un clasificador lineal en un espacio bidimensional (como un perceptrón) tiene una dimensión VC de 3, lo que significa que puede destruir cualquier conjunto de tres puntos pero no todos los conjuntos de cuatro. Modelos más complejos, como las redes neuronales, pueden tener dimensiones VC mucho más altas, reflejando su capacidad para ajustar patrones más intrincados en los datos. Sin embargo, una mayor dimensión VC también aumenta el riesgo de sobreajuste, donde el modelo captura ruido en lugar de la estructura subyacente.
La dimensión VC es particularmente relevante en el contexto del marco de aprendizaje Probablemente Aproximadamente Correcto (PAC), que proporciona garantías teóricas sobre el número de muestras de entrenamiento necesarias para lograr un nivel deseado de precisión y confianza. Según la teoría, la complejidad de muestra —el número de ejemplos necesarios para el aprendizaje— aumenta con la dimensión VC de la clase de hipótesis. Esta relación guía a los prácticos en la selección de clases de modelos apropiadas y estrategias de regularización para equilibrar la expresividad y la generalización.
En aplicaciones del mundo real, la dimensión VC informa el diseño y la evaluación de algoritmos como máquinas de vectores de soporte (SVM), árboles de decisión y redes neuronales. Por ejemplo, las SVM están estrechamente ligadas a la teoría VC, ya que su principio de maximización del margen puede interpretarse como una forma de controlar la dimensión VC efectiva del clasificador, mejorando así el rendimiento de generalización. De manera similar, las técnicas de poda en árboles de decisión pueden verse como métodos para reducir la dimensión VC y mitigar el sobreajuste.
Si bien la dimensión VC exacta de modelos complejos como las redes neuronales profundas a menudo es difícil de calcular, el concepto sigue siendo influyente en la investigación y la práctica. Sostiene el desarrollo de métodos de regularización, criterios de selección de modelos y límites teóricos sobre el rendimiento del aprendizaje. La relevancia duradera de la dimensión VC se refleja en su papel fundamental en el trabajo de organizaciones como la Asociación para el Avance de la Inteligencia Artificial y la Asociación para la Maquinaria de Computación, que promueven la investigación en teoría del aprendizaje automático y sus implicaciones prácticas.
Limitaciones y Críticas de la Dimensión VC
La dimensión Vapnik–Chervonenkis (VC) es un concepto fundamental en la teoría del aprendizaje estadístico, proporcionando una medida de la capacidad o complejidad de un conjunto de funciones (clase de hipótesis) en términos de su capacidad para destruir puntos de datos. A pesar de su importancia teórica, la dimensión VC tiene varias limitaciones notables y ha sido objeto de diversas críticas dentro de las comunidades de aprendizaje automático y estadística.
Una limitación principal de la dimensión VC es su enfoque en los peores escenarios. La dimensión VC cuantifica el mayor conjunto de puntos que puede ser destruido por una clase de hipótesis, pero esto no siempre refleja el rendimiento típico o promedio de los algoritmos de aprendizaje en entornos prácticos. Como resultado, la dimensión VC puede sobreestimar la verdadera complejidad requerida para una generalización exitosa en datos del mundo real, donde las distribuciones a menudo están lejos de ser adversariales o del peor caso. Esta desconexión puede llevar a límites excesivamente pesimistas sobre la complejidad de muestra y el error de generalización.
Otra crítica se refiere a la aplicabilidad de la dimensión VC a modelos modernos de aprendizaje automático, particularmente a las redes neuronales profundas. Mientras que la dimensión VC está bien definida para clases de hipótesis simples como clasificadores lineales o árboles de decisión, se vuelve difícil de calcular o incluso de interpretar de manera significativa para modelos altamente parametrizados. En muchos casos, las redes profundas pueden tener dimensiones VC extremadamente altas o incluso infinitas, y aún así generalizar bien en la práctica. Este fenómeno, a veces denominado «paradoja de la generalización», sugiere que la dimensión VC no capta completamente los factores que rigen la generalización en sistemas modernos de aprendizaje automático.
Además, la dimensión VC es inherentemente una medida combinatoria, ignorando la geometría y la estructura de la distribución de datos. No tiene en cuenta propiedades basadas en márgenes, regularización u otras técnicas algorítmicas que pueden afectar significativamente la generalización. Se han propuesto medidas alternativas de complejidad, como la complejidad de Rademacher o los números de cobertura, para abordar algunas de estas deficiencias incorporando aspectos dependientes de los datos o geométricos.
Finalmente, la dimensión VC asume que los puntos de datos son independientes e identicamente distribuidos (i.i.d.), una suposición que puede no cumplirse en muchas aplicaciones del mundo real, como el análisis de series temporales o tareas de predicción estructurada. Esto limita aún más la aplicabilidad directa de la teoría basada en VC en ciertos dominios.
A pesar de estas limitaciones, la dimensión VC sigue siendo una piedra angular de la teoría del aprendizaje, proporcionando valiosas perspectivas sobre los límites fundamentales de la aprendibilidad. La investigación en curso por parte de organizaciones como la Asociación para el Avance de la Inteligencia Artificial y el Instituto de Estadística Matemática continúa explorando extensiones y alternativas al marco VC, con el objetivo de alinear mejor las garantías teóricas con las observaciones empíricas en el aprendizaje automático moderno.
Direcciones Futuras y Problemas Abiertos en la Teoría VC
La dimensión Vapnik–Chervonenkis (VC) sigue siendo una piedra angular de la teoría del aprendizaje estadístico, proporcionando una medida rigurosa de la capacidad de las clases de hipótesis y su habilidad para generalizar a partir de muestras finitas. A pesar de su papel fundamental, varias direcciones futuras y problemas abiertos continúan impulsando la investigación en la teoría VC, reflejando tanto desafíos teóricos como demandas prácticas en el aprendizaje automático moderno.
Una dirección prominente es la extensión de la teoría VC a datos más complejos y estructurados. El análisis tradicional de la dimensión VC es adecuado para la clasificación binaria y espacios de hipótesis simples, pero las aplicaciones modernas a menudo involucran salidas multicategóricas, o datos con dependencias intrincadas. Desarrollar nociones generalizadas de la dimensión VC que puedan capturar la complejidad de las redes neuronales profundas, arquitecturas recurrentes y otros modelos avanzados sigue siendo un desafío abierto. Esto incluye comprender la capacidad efectiva de estos modelos y cómo se relaciona con su rendimiento empírico y capacidad de generalización.
Otra área activa de investigación es el aspecto computacional de la dimensión VC. Si bien la dimensión VC proporciona garantías teóricas, calcular o incluso aproximar la dimensión VC para clases de hipótesis arbitrarias a menudo es inabordable. Se buscan algoritmos eficientes para estimar la dimensión VC, especialmente para modelos a gran escala o de alta dimensión. Esto tiene implicaciones para la selección de modelos, regularización y el diseño de algoritmos de aprendizaje que puedan controlar adaptativamente la complejidad del modelo.
La relación entre la dimensión VC y otras medidas de complejidad, como la complejidad de Rademacher, los números de cobertura y la estabilidad algorítmica, también presenta un terreno fértil para la exploración. A medida que los modelos de aprendizaje automático se vuelven más sofisticados, entender cómo estas diferentes medidas interactúan y cuáles son las más predictivas de la generalización en la práctica es un problema abierto clave. Esto es particularmente relevante en el contexto de modelos sobreparametrizados, donde la teoría VC clásica puede no explicar completamente los fenómenos de generalización observados.
Además, la aparición de preocupaciones sobre la privacidad de los datos y la equidad introduce nuevas dimensiones a la teoría VC. Los investigadores están investigando cómo las restricciones, como la privacidad diferencial o los requisitos de equidad, afectan la dimensión VC y, en consecuencia, la aprendibilidad de las clases de hipótesis bajo estas restricciones. Esta intersección de la teoría VC con consideraciones éticas y legales probablemente crecerá en importancia a medida que los sistemas de aprendizaje automático se implementen cada vez más en dominios sensibles.
Finalmente, el desarrollo continuo de la computación cuántica y sus posibles aplicaciones en el aprendizaje automático plantea preguntas sobre la dimensión VC en espacios de hipótesis cuánticas. Comprender cómo los recursos cuánticos afectan la capacidad y la generalización de los algoritmos de aprendizaje es un área emergente de indagación teórica.
A medida que el campo evoluciona, organizaciones como la Asociación para el Avance de la Inteligencia Artificial y el Instituto de Estadística Matemática continúan apoyando la investigación y la difusión de avances en la teoría VC, asegurando que las preguntas fundamentales permanezcan en la vanguardia de la investigación en aprendizaje automático.
Fuentes y Referencias
- Instituto de Estudios Avanzados
- Sociedad Matemática Americana
- Asociación para la Maquinaria de Computación