Objasnění rozměru Vapnik–Červenokovského: Klíč k porozumění složitosti modelu a generalizaci v strojovém učení. Objevte, jak rozměr VC formuje hranice toho, co se algoritmy mohou naučit.
- Úvod do rozměru Vapnik–Červenokovského
- Historické původy a teoretické základy
- Formální definice a matematický rámec
- VC rozměr v binární klasifikaci
- Shattering, rostoucí funkce a jejich význam
- VC rozměr a kapacita modelu: Praktické důsledky
- Vztahy k overfittingu a obecně uzavřeným mezerám
- VC rozměr v reálných algoritmech strojového učení
- Omezení a kritiky VC rozměru
- Budoucí směry a otevřené problémy v teorii VC
- Zdroje & reference
Úvod do rozměru Vapnik–Červenokovského
Rozměr Vapnik–Červenokovský (VC rozměr) je základní koncept ve statistické teorii učení, který byl představen Vladimirem Vapnikem a Alexeyem Červenokovským na počátku 70. let 20. století. Poskytuje rigorózní matematický rámec pro kvantifikaci kapacity nebo složitosti množiny funkcí (třídy hypotéz) z hlediska její schopnosti klasifikovat datové body. VC rozměr je definován jako největší počet bodů, které mohou být shatterovány (tj. správně klasifikovány všemi možnými způsoby) třídou hypotéz. Tento koncept je středobodem pro porozumění schopnosti generalizace učebních algoritmů, protože spojuje vyjadřovací schopnost modelu s jeho rizikem overfittingu.
Formálněji, pokud třída hypotéz může shatterovat množinu n bodů, ale nemůže shatterovat žádnou množinu n+1 bodů, pak její VC rozměr je n. Například třída lineárních klasifikátorů ve dvourozměrném prostoru má VC rozměr 3, což znamená, že může shatterovat jakoukoli množinu tří bodů, ale ne všechny množiny čtyř bodů. VC rozměr tedy slouží jako měřítko bohatosti třídy hypotéz, nezávisle na konkrétní distribuci dat.
Význam VC rozměru spočívá v jeho roli při poskytování teoretických záruk pro algoritmy strojového učení. Je klíčovou součástí odvození mezí na chybu generalizace, což je rozdíl mezi chybou na tréninkových datech a očekávanou chybou na neviděných datech. Slavná VC nerovnost, například, vztahuje VC rozměr k pravděpodobnosti, že empirické riziko (tréninková chyba) se odchyluje od skutečného rizika (chyba generalizace). Tento vztah je základem principu minimalizace strukturálního rizika, což je pilíř moderní statistické teorie učení, který se snaží vyvážit složitost modelu a chybu při trénování, aby dosáhl optimální generalizace.
Koncept VC rozměru se široce uplatňuje v analýze různých učebních algoritmů, včetně podporovaných vektorových strojů, neuronových sítí a rozhodovacích stromů. Je také základem pro rozvoj rámce Pravděpodobně Přibližně Správné (PAC) učení, který formalizuje podmínky, za nichž lze očekávat, že učební algoritmus bude fungovat dobře. Teoretické základy poskytované VC rozměrem byly klíčové pro pokrok v oblasti strojového učení a jsou uznávány předními výzkumnými institucemi, jako jsou Institut pro pokročilé studium a Asociace pro pokrok umělé inteligence.
Historické původy a teoretické základy
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, který byl představen na počátku 70. let Vladimirem Vapnikem a Alexeyem Červenokovským. Jejich průkopnická práce vznikla na Institutu řídící vědy Ruské akademie věd, kde se snažili formalizovat principy, které leží v základech rozpoznávání vzorů a strojového učení. VC rozměr poskytuje rigorózní matematický rámec pro kvantifikaci kapacity množiny funkcí (třídy hypotéz) na přizpůsobení datům, což je zásadní pro porozumění schopnosti generalizace učebních algoritmů.
VC rozměr v jádru měří největší počet bodů, které mohou být shatterovány (tj. správně klasifikovány všemi možnými způsoby) třídou hypotéz. Pokud třída funkcí může shatterovat množinu velikosti d, ale ne d+1, její VC rozměr je d. Tento koncept umožňuje výzkumníkům analyzovat vyváženost mezi složitostí modelu a rizikem overfittingu, což je centrální problém ve strojovém učení. Zavedení VC rozměru znamenalo významný pokrok oproti dřívějším, méně formálním přístupům k teorii učení, poskytujícím most mezi empirickým výkonem a teoretickými zárukami.
Teoretické základy VC rozměru jsou úzce zpřístupněny k rozvoji rámce Pravděpodobně Přibližně Správné (PAC) učení, který formalizuje podmínky, za nichž lze očekávat, že učební algoritmus bude fungovat dobře na neviděných datech. VC rozměr slouží jako klíčový parametr v větách, které omezují chybu generalizace klasifikátorů, přičemž se ukazuje, že konečný VC rozměr je nezbytný pro učitelnost v PAC smyslu. Tento postřeh měl hluboký dopad na návrh a analýzu algoritmů v oblastech od počítačového vidění po zpracování přirozeného jazyka.
Práce Vapnika a Červenokovského položila základy pro vývoj podporovaných vektorových strojů a dalších metod založených na jádrech, které se spoléhají na principy kontroly kapacity a minimalizace strukturálního rizika. Jejich přínosy byly uznány předními vědeckými organizacemi, a VC rozměr zůstává centrálním tématem v kurikulu pokročilých kurzů strojového učení a statistiky po celém světě. Americká matematická společnost a Asociace pro pokrok umělé inteligence jsou mezi organizacemi, které zdůraznily význam těchto teoretických pokroků ve svých publikacích a konferencích.
Formální definice a matematický rámec
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, poskytující rigorózní měřítko kapacity nebo složitosti množiny funkcí (třídy hypotéz) z hlediska její schopnosti klasifikovat datové body. Formálně je VC rozměr definován pro třídu indikátorových funkcí (nebo množin) jako největší počet bodů, které mohou být shatterovány touto třídou. „Shatterovat“ množinu bodů znamená, že pro každé možné označení těchto bodů existuje funkce v třídě, která správně přiřazuje tato označení.
Nechť H je třída hypotéz binárně hodnotících funkcí mapujících z prostoru vstupů X na {0,1}. Množina bodů S = {x₁, x₂, …, xₙ} je považována za shatterovanou třídou H, pokud pro každý možný podmnožin A z S existuje funkce h ∈ H, taková že h(x) = 1 právě tehdy, když x ∈ A. VC rozměr H, označovaný jako VC(H), je maximální kardinalita n, taková že existuje množina n bodů v X, které jsou shatterovány H. Pokud mohou být shatterovány libovolně velké konečné množiny, je VC rozměr nekonečný.
Matematicky VC rozměr poskytuje spojení mezi vyjadřovací schopností třídy hypotéz a její schopností generalizace. Vyšší VC rozměr naznačuje vyjadřovací třídu, schopnou přizpůsobit složitějším vzorcům, ale také zvyšuje riziko overfittingu. Naopak, nižší VC rozměr naznačuje omezenou vyjadřovací schopnost a potenciálně lepší generalizaci, ale možná na úkor underfittingu. VC rozměr je klíčový pro odvození obecných mezí generalizace, jako jsou ty, které jsou formalizovány ve fundamentálních větách statistické teorie učení, které vztahují VC rozměr k vzorkové složitosti potřebné pro učení s danou přesností a přesvědčením.
Koncept byl představen Vladimirem Vapnikem a Alexeyem Červenokovským v 70. letech a podkládá teoretickou analýzu učebních algoritmů, včetně podporovaných vektorových strojů a rámců empirické minimalizace rizika. VC rozměr je široce uznáván a využíván v oblasti strojového učení a podrobně diskutován organizacemi, jako je Institut matematické statistiky a Asociace pro pokrok umělé inteligence, které jsou obě předními autoritami ve výzkumu statistiky a umělé inteligence.
VC rozměr v binární klasifikaci
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, který je zvlášť relevantní pro analýzu modelů binární klasifikace. Představen Vladimirem Vapnikem a Alexeyem Červenokovským na počátku 70. let, VC rozměr kvantifikuje kapacitu nebo složitost množiny funkcí (třídy hypotéz) měřením její schopnosti shatterovat konečné množiny datových bodů. V kontextu binární klasifikace se „shattering“ týká schopnosti klasifikátoru správně označit všechny možné přiřazení binárních označení (0 nebo 1) k dané množině bodů.
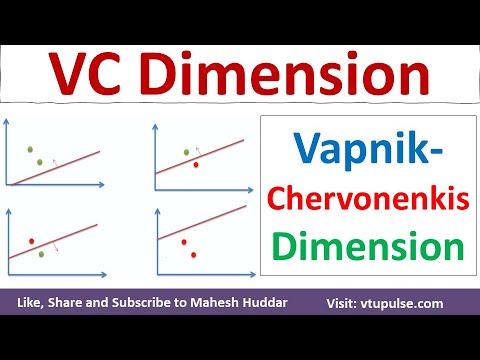
Formálně je VC rozměr třídy hypotéz největší počet bodů, které může tato třída shatterovat. Například zvažte třídu lineárních klasifikátorů (perceptroty) ve dvourozměrném prostoru. Tato třída může shatterovat jakoukoli množinu tří bodů v obecné pozici, ale ne všechny množiny čtyř bodů. Proto je VC rozměr lineárních klasifikátorů ve dvou rozměrech tři. VC rozměr poskytuje měřítko vyjadřovací schopnosti modelu: vyšší VC rozměr naznačuje flexibilnější model, který může přizpůsobit složitějším vzorcům, ale také zvyšuje riziko overfittingu.
V binární klasifikaci hraje VC rozměr zásadní roli v porozumění vyváženosti mezi složitostí modelu a generalizací. Podle teorie, pokud je VC rozměr příliš vysoký ve srovnání s počtem tréninkových vzorků, může model dokonale přizpůsobit tréninková data, ale selhat v generalizaci na neviděná data. Naopak model s nízkým VC rozměrem může underfitovat, selhávat v zachycování důležitých vzorců v datech. VC rozměr tedy poskytuje teoretické záruky na chybu generalizace, jak je formalizováno v VC nerovnosti a souvisejících mezích.
Koncept VC rozměru je centrální pro vývoj učebních algoritmů a analýzu jejich výkonu. Podkládá rámec Pravděpodobně Přibližně Správné (PAC) učení, který charakterizuje podmínky, za nichž může učební algoritmus dosáhnout nízké chyby generalizace s vysokou pravděpodobností. VC rozměr je také využíván při návrhu a analýze podporovaných vektorových strojů (SVM), což je široce používaná třída binárních klasifikátorů, stejně jako při studiu neuronových sítí a dalších modelů strojového učení.
Význam VC rozměru v binární klasifikaci je uznáván předními výzkumnými institucemi a organizacemi v oblasti umělé inteligence a strojového učení, jako je Asociace pro pokrok umělé inteligence a Asociace pro výpočetní techniku. Tyto organizace podporují výzkum a šíření základních konceptů, jako je VC rozměr, které nadále formují teoretické základy a praktické aplikace strojového učení.
Shattering, rostoucí funkce a jejich význam
Koncepty shattering a rostoucí funkce jsou ústřední pro pochopení rozměru Vapnik–Červenokovského (VC), základní míry ve statistické teorii učení. VC rozměr, který byl představen Vladimirem Vapnikem a Alexeyem Červenokovským, kvantifikuje kapacitu množiny funkcí (třídy hypotéz) přizpůsobit data a je zásadní pro analýzu schopnosti generalizace učebních algoritmů.
Shattering se týká schopnosti třídy hypotéz dokonale klasifikovat všechny možné označení konečné množiny bodů. Formálně se říká, že množina bodů je shatterována třídou hypotéz, pokud pro každé možné přiřazení binárních značek k bodu existuje funkce v třídě, která správně odděluje body podle těchto označení. Například v případě lineárních klasifikátorů ve dvou rozměrech mohou být jakékoli tři nekolineární body shatterovány, ale ne všechny množiny čtyř bodů mohou být.
Rostoucí funkce, také známá jako koeficient roztržení, měří maximální počet odlišných označení (dichotomií), které třída hypotéz může realizovat na jakékoli množině n bodů. Pokud třída hypotéz může shatterovat každou množinu n bodů, roste rostoucí funkce na 2n. Nicméně, jak n roste, většina tříd hypotéz dosáhne bodu, kdy už nemohou shatterovat všechna možná označení, a rostoucí funkce roste pomaleji. VC rozměr je definován jako největší celé číslo d, takové že rostoucí funkce je rovna 2d; jinými slovy, je to velikost největší množiny, která může být shatterována třídou hypotéz.
Tyto koncepty jsou významné, protože poskytují rigorózní způsob analýzy složitosti a vyjadřovací síly učebních modelů. Vyšší VC rozměr naznačuje vyjadřovací model, schopný přizpůsobit složitějším vzorcům, ale také zvyšuje riziko overfittingu. Naopak nízký VC rozměr naznačuje omezenou kapacitu, což může vést k underfittingu. VC rozměr je přímo spojen s obecnými mezemi: pomáhá stanovit, kolik tréninkových dat je potřeba zajistit, aby výkon modelu na neviděných datech byl blízký jeho výkonu na tréninkové sadě. Tento vztah je formalizován ve větách, jako je fundamentální věta statistického učení, která podkládá většinu moderní teorie strojového učení.
Studium shattering a rostoucích funkcí a jejich spojení s VC rozměrem je základní v práci organizací, jako je Asociace pro pokrok umělé inteligence a Institut matematické statistiky, které propagují výzkum a šíření pokroků ve statistické teorii učení a jejích aplikacích.
VC rozměr a kapacita modelu: Praktické důsledky
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, poskytující rigorózní měřítko kapacity nebo složitosti množiny funkcí (třída hypotéz), které může strojový učební model realizovat. V praktických termínech VC rozměr kvantifikuje největší počet bodů, které mohou být shatterovány (tj. správně klasifikovány všemi možnými způsoby) modelem. Toto měřítko je zásadní pro pochopení vyváženosti mezi schopností modelu přizpůsobit tréninková data a jeho schopností generalizovat na neviděná data.
Vyšší VC rozměr naznačuje vyjadřovací modelovou třídu, schopnou reprezentovat složitější vzorce. Například lineární klasifikátor ve dvourozměrném prostoru má VC rozměr 3, což znamená, že může shatterovat jakoukoli množinu tří bodů, ale ne všechny množiny čtyř. Naproti tomu složitější modely, jako jsou neuronové sítě s mnoha parametry, mohou mít mnohem vyšší VC rozměry, což odráží jejich větší kapacitu přizpůsobit různorodým datovým sadám.
Praktické důsledky VC rozměru jsou nejvíce viditelné v kontextu overfittingu a underfittingu. Pokud je VC rozměr modelu mnohem větší než počet tréninkových vzorků, může model overfitovat – memorování tréninkových dat, spíše než učení generalizovatelných vzorců. Naopak, pokud je VC rozměr příliš nízký, může model underfitovat, selhávat v zachycování základní struktury dat. Výběr modelu se vhodným VC rozměrem vzhledem k velikosti datové sady je tedy nezbytný pro dosažení dobrého výkonu generalizace.
VC rozměr také podkládá teoretické záruky v teorii učení, jako je rámec Pravděpodobně Přibližně Správné (PAC) učení. Poskytuje meze na počet tréninkových vzorků potřebných k zajištění, že empirické riziko (chyba na tréninkové sadě) je blízké skutečnému riziku (očekávané chybě na nových datech). Tyto výsledky pomáhají praktikům odhadnout vzorkovou složitost potřebnou pro spolehlivé učení, zejména v aplikacích s vysokými nároky, jako je diagnostika v medicíně nebo autonomní systémy.
V praxi, zatímco přesný VC rozměr je často obtížné spočítat pro složité modely, jeho konceptuální role informuje návrh a výběr algoritmů. Techniky regularizace, kritéria výběru modelů a strategie křížové validace jsou všechny ovlivněny základními principy kontroly kapacity vyjádřenými VC rozměrem. Tento koncept byl představen Vladimirem Vapnikem a Alexeyem Červenokovským, jejichž práce položila základy moderní statistické teorii učení a nadále ovlivňuje výzkum a aplikace ve strojovém učení (Institut matematické statistiky).
Vztahy k overfittingu a obecně uzavřeným mezerám
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, který přímo ovlivňuje naše porozumění overfittingu a generalizaci v modelech strojového učení. VC rozměr kvantifikuje kapacitu nebo složitost množiny funkcí (třídy hypotéz) měřením největší množiny bodů, které mohou být shatterovány – tj. správně klasifikovány všemi možnými způsoby – funkcemi v této třídě. Toto měřítko je zásadní pro analýzu toho, jak dobře model trénovaný na konečné datové sadě bude fungovat na neviděných datech, což je vlastnost známá jako generalizace.
Overfitting nastává, když model učí nejen základní vzorce, ale také šum v tréninkových datech, což vede k špatnému výkonu na nových, neviděných datech. VC rozměr poskytuje teoretický rámec pro pochopení a zmírnění overfittingu. Pokud je VC rozměr třídy hypotéz mnohem větší než počet tréninkových vzorků, model má dostatečnou kapacitu pro přizpůsobení náhodného šumu, což zvyšuje riziko overfittingu. Naopak, pokud je VC rozměr příliš nízký, model může underfitovat, selhat v zachycování esenciální struktury dat.
Vztah mezi VC rozměrem a generalizací je formalizován prostřednictvím obecných mezí. Tyto meze, jako ty, které vycházejí z fundamentální práce Vladimira Vapnika a Alexeyho Červenokovského, uvádějí, že s vysokou pravděpodobností je rozdíl mezi empirickým rizikem (chybou na tréninkové sadě) a skutečným rizikem (očekávanou chybou na nových datech) malý, pokud je počet tréninkových vzorků dostatečně velký ve vztahu k VC rozměru. Konkrétně chyba generalizace klesá, když se počet vzorků zvyšuje, za předpokladu, že VC rozměr zůstává fixní. Tento postřeh podkládá princip, že složitější modely (s vyšším VC rozměrem) vyžadují více dat k dobré generalizaci.
- VC rozměr je centrální pro teorii univerzální konvergence, která zajišťuje, že empirické průměry konvergují k očekávaným hodnotám uniformně nad všemi funkcemi v třídě hypotéz. Tento vlastnost je zásadní pro zajištění, že minimalizace chyby na tréninkové sadě vede k nízké chybě na neviděných datech.
- Tento koncept je také integrální pro rozvoj minimalizace strukturálního rizika, strategie, která vyvažuje složitost modelu a tréninkovou chybu s cílem dosáhnout optimální generalizace, jak bylo formalizováno v teorii podporovaných vektorových strojů a dalších učebních algoritmech.
Význam VC rozměru pro pochopení overfittingu a generalizace je uznáván předními výzkumnými institucemi a je základní součástí kurikula statistické teorie učení, jak je uvedeno organizacemi, jako je Institut pro pokročilé studium a Asociace pro pokrok umělé inteligence. Tyto organizace přispívají k průběžnému rozvoji a šíření teoretických pokroků ve strojovém učení.
VC rozměr v reálných algoritmech strojového učení
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, poskytující rigorózní měřítko kapacity nebo složitosti množiny funkcí (třídy hypotéz), které může strojový učební algoritmus realizovat. V reálném strojovém učení hraje VC rozměr zásadní roli v pochopení schopnosti generalizace algoritmů – jak dobře model trénovaný na konečném vzorku se očekává, že bude fungovat na neviděných datech.
V praktických termínech VC rozměr pomáhá kvantifikovat vyváženost mezi složitostí modelu a rizikem overfittingu. Například lineární klasifikátor ve dvourozměrném prostoru (např. perceptron) má VC rozměr 3, což znamená, že může shatterovat jakoukoli množinu tří bodů, ale ne všechny množiny čtyř. Složitější modely, jako jsou neuronové sítě, mohou mít mnohem vyšší VC rozměry, což odráží jejich schopnost přizpůsobit složitější vzorce v datech. Nicméně, vyšší VC rozměr také zvyšuje riziko overfittingu, kdy model zachycuje šum namísto základní struktury.
VC rozměr je obzvlášť relevantní v kontextu rámce Pravděpodobně Přibližně Správné (PAC) učení, který poskytuje teoretické záruky o počtu tréninkových vzorků potřebných k dosažení požadované úrovně přesnosti a důvěry. Podle teorie roste vzorková složitost – počet příkladů potřebných k učení – s VC rozměrem třídy hypotéz. Tento vztah vede praktikanty k výběru vhodných tříd modelů a strategií regularizace, aby vyvážili vyjadřovací schopnost a generalizaci.
V reálných aplikacích VC rozměr informuje návrh a hodnocení algoritmů, jako jsou podporované vektorové stroje (SVM), rozhodovací stromy a neuronové sítě. Například SVM jsou úzce spojeny s teorií VC, protože jejich princip maximalizace okraje lze interpretovat jako způsob řízení efektivního VC rozměru klasifikátoru, čímž se zlepšuje výkon generalizace. Podobně techniky prořezávání v rozhodovacích stromech lze považovat za metody pro snížení VC rozměru a zmírnění overfittingu.
I když přesný VC rozměr složitých modelů, jako jsou hluboké neuronové sítě, je často obtížné spočítat, koncept zůstává vlivný či v oblasti průzkumu a praxe. Podkládá rozvoj metod regularizace, kritérií výběru modelů a teoretických mezí na výkonnost učení. Trvalá relevance VC rozměru je reflektována v jeho základní roli v práci organizací, jako je Asociace pro pokrok umělé inteligence a Asociace pro výpočetní techniku, které propagují výzkum teorie strojového učení a jejích praktických důsledků.
Omezení a kritiky VC rozměru
Rozměr Vapnik–Červenokovský (VC) je základní koncept ve statistické teorii učení, poskytující měřítko kapacity nebo složitosti množiny funkcí (třídy hypotéz) z hlediska její schopnosti shatterovat datové body. Navzdory své teoretické významnosti má VC rozměr několik značných omezení a byl předmětem různých kritik v rámci strojového učení a statistických komunit.
Jedním z primárních omezení VC rozměru je jeho zaměření na nejhorší scénáře. VC rozměr kvantifikuje největší množinu bodů, které mohou být shatterovány třídou hypotéz, ale to ne vždy odráží typickou nebo průměrnou výkonnost učení algoritmů v praktických nastaveních. V důsledku toho může VC rozměr nadhodnocovat skutečnou složitost potřebnou pro úspěšnou generalizaci v reálných datech, kde jsou distribuce často daleko od nepřátelských nebo nejhorších případů. Tato nesrovnalost může vést k příliš pesimistickým mezím na vzorkovou složitost a chybu generalizace.
Další kritikou se týká použitelnosti VC rozměru pro moderní modely strojového učení, zejména hluboké neuronové sítě. Zatímco VC rozměr je dobře definován pro jednoduché třídy hypotéz, jako jsou lineární klasifikátory nebo rozhodovací stromy, stává se obtížným jeho výpočet nebo dokonce smysluplná interpretace pro vysoce parametrizované modely. V mnoha případech mohou mít hluboké sítě extrémně vysoké nebo dokonce nekonečné VC rozměry, přesto však v praxi dobře generalizují. Tento jev, někdy nazývaný „paradox generalizace“, naznačuje, že VC rozměr úplně neodráží faktory, které řídí generalizaci v současných systémech strojového učení.
Kromě toho je VC rozměr inherentně kombinatorní mírou, která ignoruje geometrii a strukturu distribuce dat. Nezohledňuje vlastnosti založené na okrajích, regularizace nebo další algoritmické techniky, které mohou významně ovlivnit generalizaci. Alternativní míry složitosti, jako je Rademacherova složitost nebo pokrývací čísla, byly navrženy tak, aby adresovaly některá z těchto nedostatků tím, že začleňují aspekty závislé na datech nebo geometrické.
Nakonec VC rozměr předpokládá, že datové body jsou nezávislé a identicky distribuované (i.i.d.), což je předpoklad, který nemusí platit v mnoha reálných aplikacích, jako je analýza časových řad nebo úkoly strukturované predikce. To dále omezuje přímou použitelnost teorie založené na VC v určitých oblastech.
Navzdory těmto omezením zůstává VC rozměr základem teorie učení, poskytující cenné poznatky o fundamentálních limitech učitelnosti. Pokračující výzkum organizací, jako je Asociace pro pokrok umělé inteligence a Institut matematické statistiky, nadále zkoumá rozšíření a alternativy k VC rámci, s cílem lépe sladit teoretické záruky s empirickými pozorováními v moderním strojovém učení.
Budoucí směry a otevřené problémy v teorii VC
Rozměr Vapnik–Červenokovský (VC) zůstává základním kamenem statistické teorie učení, poskytujícím rigorózní měřítko schopnosti tříd hypotéz a jejich schopnosti generalizovat z konečných vzorků. Navzdory své základní roli však několik budoucích směrů a otevřených problémů nadále formuje výzkum v teorii VC, odrážejících teoretické výzvy i praktické požadavky v moderním strojovém učení.
Jedním významným směrem je rozšíření teorie VC na složitější a strukturované datové domény. Tradiční analýza VC rozměru je dobře přizpůsobena pro binární klasifikaci a jednoduché prostory hypotéz, ale moderní aplikace často zahrnují více tříd, strukturované výstupy nebo data se složitými závislostmi. Vývoj zobecněných pojmů VC rozměru, které dokážou zachytit složitost hlubokých neuronových sítí, rekurentních architektur a dalších pokročilých modelů, zůstává otevřenou výzvou. To zahrnuje porozumění efektivní kapacitě těchto modelů a tomu, jak to souvisí s jejich empirickým výkonem a schopností generalizace.
Další aktivní oblastí výzkumu je výpočetní aspekt VC rozměru. Zatímco VC rozměr poskytuje teoretické záruky, výpočet nebo dokonce přiblížení VC rozměru pro libovolné třídy hypotéz je často nesplnitelný. Efektivní algoritmy pro odhad VC rozměru, zejména pro velké nebo vysoce dimenzionální modely, jsou velmi žádané. To má důsledky pro výběr modelů, regularizaci a návrh učebních algoritmů, které mohou adaptivně řídit složitost modelu.
Vztah mezi VC rozměrem a jinými mírami složitosti, jako je Rademacherova složitost, pokrývací čísla a algoritmická stabilita, také představuje úrodnou půdu pro zkoumání. Jak se modely strojového učení stávají sofistikovanějšími, porozumění tomu, jak tyto různé míry interagují a které jsou nejpředvídatelnější z hlediska generalizace v praxi, je klíčovým otevřeným problémem. To je obzvlášť relevantní v kontextu přeparametrizovaných modelů, kde klasická teorie VC nemusí plně vysvětlit pozorované jevy generalizace.
Navíc, vznik obav o ochranu dat a spravedlnosti přidává nové dimenze k teorii VC. Výzkumníci zkoumají, jak omezení, jako je diferenciální soukromí nebo požadavky na spravedlnost, ovlivňují VC rozměr a tím pádem učitelnost tříd hypotéz pod těmito omezeními. Tato křižovatka teorie VC s etickými a právními úvahami pravděpodobně poroste na významu, jak se systémy strojového učení stále více používají v citlivých oblastech.
Nakonec, probíhající vývoj kvantového počítačství a jeho potenciální aplikace v strojovém učení vyvolává otázky ohledně VC rozměru v kvantových hypotézových prostorech. Pochopení toho, jak kvantové zdroje ovlivňují kapacitu a generalizaci učebních algoritmů, je nově vznikající oblast teoretického zkoumání.
Jak se pole vyvíjí, organizace, jako je Asociace pro pokrok umělé inteligence a Institut matematické statistiky nadále podporují výzkum a šíření pokroků v teorii VC, zajišťujíc, že základní otázky zůstávají na předním místě ve výzkumu strojového učení.
Zdroje & reference