Entmystifizierung der Vapnik–Chervonenkis-Dimension: Der Schlüssel zum Verständnis der Modellkomplexität und Generalisierung im maschinellen Lernen. Entdecken Sie, wie die VC-Dimension die Grenzen dessen, was Algorithmen lernen können, formt.
- Einführung in die Vapnik–Chervonenkis-Dimension
- Historische Ursprünge und theoretische Grundlagen
- Formale Definition und mathematischer Rahmen
- VC-Dimension in der binären Klassifikation
- Shattering, Wachstumsfunktionen und deren Bedeutung
- VC-Dimension und Modellkapazität: Praktische Implikationen
- Verbindungen zu Overfitting und Generalisierungsgrenzen
- VC-Dimension in realen maschinellen Lernalgorithmen
- Einschränkungen und Kritiken der VC-Dimension
- Zukünftige Richtungen und offene Probleme in der VC-Theorie
- Quellen & Referenzen
Einführung in die Vapnik–Chervonenkis-Dimension
Die Vapnik–Chervonenkis-Dimension (VC-Dimension) ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das von Vladimir Vapnik und Alexey Chervonenkis in den frühen 1970er Jahren eingeführt wurde. Sie bietet einen rigorosen mathematischen Rahmen zur Quantifizierung der Kapazität oder Komplexität einer Funktionenset (Hypothesenklasse) in Bezug auf ihre Fähigkeit, Datenpunkte zu klassifizieren. Die VC-Dimension wird definiert als die größte Anzahl von Punkten, die von der Hypothesenklasse „zertrümmert“ (d.h. in allen möglichen Varianten korrekt klassifiziert) werden kann. Dieses Konzept ist zentral für das Verständnis der Generalisierungsfähigkeit von Lernalgorithmen, da es die Ausdruckskraft eines Modells mit seinem Risiko des Overfittings verbindet.
Formal ausgedrückt, wenn eine Hypothesenklasse eine Menge von n Punkten zertrümmern kann, aber keine Menge von n+1 Punkten, dann ist ihre VC-Dimension n. Zum Beispiel hat die Klasse der linearen Klassifizierer im zweidimensionalen Raum eine VC-Dimension von 3, was bedeutet, dass sie jede Menge von drei Punkten zertrümmern kann, jedoch nicht alle Mengen von vier Punkten. Die VC-Dimension dient somit als Maß für die Reichhaltigkeit einer Hypothesenklasse, unabhängig von der spezifischen Datenverteilung.
Die Bedeutung der VC-Dimension liegt in ihrer Rolle, theoretische Garantien für maschinelle Lernalgorithmen bereitzustellen. Sie ist ein Schlüsselaspekt bei der Ableitung von Grenzen für den Generalisierungsfehler, der die Differenz zwischen dem Fehler in den Trainingsdaten und dem erwarteten Fehler auf ungesehenen Daten ist. Die berühmte VC-Ungleichung beispielsweise bezieht sich auf die VC-Dimension in Verbindung mit der Wahrscheinlichkeit, dass das empirische Risiko (Trainingsfehler) vom wahren Risiko (Generaliserungsfehler) abweicht. Diese Beziehung bildet die Grundlage für das Prinzip der strukturellen Risiko-Minimierung, einem Grundpfeiler der modernen Theorie des statistischen Lernens, die darauf abzielt, Modellkomplexität und Trainingsfehler auszubalancieren, um eine optimale Generalisierung zu erreichen.
Das Konzept der VC-Dimension wurde in der Analyse verschiedener Lernalgorithmen, einschließlich Support Vector Machines, neuronalen Netzwerken und Entscheidungsbäumen, weit verbreitet übernommen. Es ist auch grundlegend für die Entwicklung des Probably Approximately Correct (PAC) Lernrahmenwerks, das die Bedingungen formalisiert, unter denen ein Lernalgorithmus voraussichtlich gut abschneiden kann. Die theoretischen Grundlagen, die durch die VC-Dimension bereitgestellt werden, waren entscheidend für den Fortschritt in der maschinellen Lernforschung und werden von führenden Forschungsinstituten wie dem Institute for Advanced Study und der Association for the Advancement of Artificial Intelligence anerkannt.
Historische Ursprünge und theoretische Grundlagen
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das in den frühen 1970er Jahren von Vladimir Vapnik und Alexey Chervonenkis eingeführt wurde. Ihre bahnbrechende Arbeit entstand am Institut für Regelungswissenschaften der Russischen Akademie der Wissenschaften, wo sie suchten, die Prinzipien hinter der Mustererkennung und dem maschinellen Lernen zu formalisieren. Die VC-Dimension bietet einen rigorosen mathematischen Rahmen zur Quantifizierung der Kapazität von Funktionsmengen (Hypothesenklassen), um Daten anzupassen, was entscheidend für das Verständnis der Generalisierungsfähigkeit von Lernalgorithmen ist.
Im Kern misst die VC-Dimension die größte Anzahl von Punkten, die von einer Hypothesenklasse zertrümmert werden kann (d.h. in allen möglichen Varianten korrekt klassifiziert). Wenn eine Funktionensammlung eine Menge der Größe d zertrümmern kann, aber nicht d+1, dann ist ihre VC-Dimension d. Dieses Konzept erlaubt es Forschern, den Trade-off zwischen Modellkomplexität und Overfitting-Risiko zu analysieren, ein zentrales Anliegen im maschinellen Lernen. Die Einführung der VC-Dimension stellte einen erheblichen Fortschritt gegenüber früheren, weniger formalen Ansätzen zur Lernensdarstellung dar und bot eine Brücke zwischen empirischer Leistung und theoretischen Garantien.
Die theoretischen Grundlagen der VC-Dimension sind eng mit der Entwicklung des Probably Approximately Correct (PAC) Lernrahmenwerks verbunden, das die Bedingungen formalisiert, unter denen ein Lernalgorithmus voraussichtlich gut auf ungesehenen Daten abschneidet. Die VC-Dimension dient als Schlüsselparameter in Theoremen, die den Generalisierungsfehler von Klassifizierern begrenzen, und stellt fest, dass eine endliche VC-Dimension notwendig ist, um im PAC-Sinn erlernbar zu sein. Diese Einsicht hat tiefgreifende Auswirkungen auf das Design und die Analyse von Algorithmen in verschiedenen Bereichen, die von der Computer Vision bis zur Verarbeitung natürlicher Sprache reichen.
Die Arbeit von Vapnik und Chervonenkis legte das Fundament für die Entwicklung von Support Vector Machines und anderen kernelbasierten Methoden, die auf den Prinzipien der Kapazitätskontrolle und der strukturellen Risiko-Minimierung beruhen. Ihre Beiträge wurden von führenden wissenschaftlichen Organisationen anerkannt, und die VC-Dimension bleibt ein zentrales Thema im Lehrplan fortgeschrittener Kurse in maschinellem Lernen und Statistik weltweit. Die American Mathematical Society und die Association for the Advancement of Artificial Intelligence gehören zu den Organisationen, die die Bedeutung dieser theoretischen Fortschritte in ihren Veröffentlichungen und Konferenzen hervorgehoben haben.
Formale Definition und mathematischer Rahmen
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das eine rigorose Messgröße für die Kapazität oder Komplexität einer Gruppe von Funktionen (Hypothesenklasse) in Bezug auf ihre Fähigkeit, Datenpunkte zu klassifizieren, bietet. Formal wird die VC-Dimension für eine Klasse von Indikatorfunktionen (oder Mengen) definiert als die größte Anzahl von Punkten, die durch die Klasse zertrümmert werden kann. Eine Menge von Punkten zu „zertrümmern“ bedeutet, dass es für jede mögliche Kennzeichnung dieser Punkte eine Funktion in der Klasse gibt, die diese Beschriftungen korrekt zuweist.
Sei H eine Hypothesenklasse von binären Funktionen, die von einem Eingaberaum X auf {0,1} abbildet. Eine Menge von Punkten S = {x₁, x₂, …, xₙ} wird als von H zertrümmert angesehen, wenn es für jede mögliche Teilmenge A von S eine Funktion h ∈ H gibt, so dass h(x) = 1, wenn und nur wenn x ∈ A. Die VC-Dimension von H, bezeichnet als VC(H), ist die maximale Mächtigkeit n, für die es eine Menge von n Punkten in X gibt, die von H zertrümmert wird. Wenn beliebig große endliche Mengen zertrümmert werden können, ist die VC-Dimension unendlich.
Mathematisch betrachtet stellt die VC-Dimension eine Brücke zwischen der Ausdruckskraft einer Hypothesenklasse und ihrer Generalisierungsfähigkeit dar. Eine höhere VC-Dimension deutet auf eine ausdrucksstärkere Klasse hin, die in der Lage ist, komplexere Muster anzupassen, aber auch ein höheres Risiko für Overfitting beinhaltet. Umgekehrt deutet eine niedrigere VC-Dimension auf eine begrenzte Ausdruckskraft hin und möglicherweise eine bessere Generalisierung, aber möglicherweise auf Kosten des Underfittings. Die VC-Dimension ist zentral für die Ableitung von Generalisierungsgrenzen, wie sie in den grundlegenden Theoremen der Theorie des statistischen Lernens formalisiert sind, die die VC-Dimension mit der für das Lernen erforderlichen Stichprobenkomplexität in Bezug auf eine gegebene Genauigkeit und Zuversicht in Verbindung bringen.
Das Konzept wurde von Vladimir Vapnik und Alexey Chervonenkis in den 1970er Jahren eingeführt und bildet die Grundlage für die theoretische Analyse von Lernalgorithmen, einschließlich Support Vector Machines und Frameworks zur empirischen Risiko-Minimierung. Die VC-Dimension wird allgemein anerkannt und in der Theorie des maschinellen Lernens verwendet und ausführlich von Organisationen wie dem Institute of Mathematical Statistics und der Association for the Advancement of Artificial Intelligence diskutiert, die jeweils führende Autoritäten in der Statistik- und künstlichen Intelligenzforschung sind.
VC-Dimension in der binären Klassifikation
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das insbesondere relevant für die Analyse binärer Klassifikationsmodelle ist. Eingeführt von Vladimir Vapnik und Alexey Chervonenkis in den frühen 1970er Jahren quantifiziert die VC-Dimension die Kapazität oder Komplexität einer Struktur von Funktionen (Hypothesenklasse), indem sie ihre Fähigkeit misst, endliche Mengen von Datenpunkten zu zertrümmern. Im Kontext der binären Klassifikation bezieht sich „Shattering“ auf die Fähigkeit eines Klassifizierers, alle möglichen Zuordnungen binärer Labels (0 oder 1) zu einer gegebenen Menge von Punkten korrekt zu kennzeichnen.
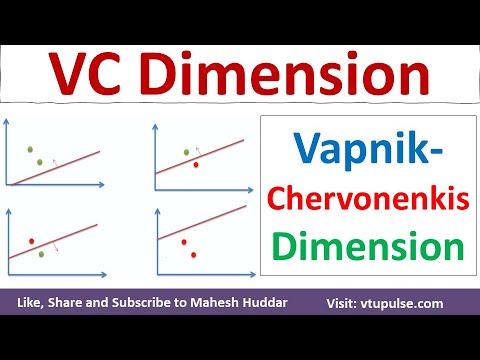
Formal ist die VC-Dimension einer Hypothesenklasse die größte Anzahl von Punkten, die von dieser Klasse zertrümmert werden kann. Betrachten wir zum Beispiel die Klasse der linearen Klassifizierer (Perzeptrons) in einem zweidimensionalen Raum. Diese Klasse kann jede Menge von drei Punkten in allgemeiner Position zertrümmern, jedoch nicht alle Mengen von vier Punkten. Daher hat die VC-Dimension linearer Klassifizierer in zwei Dimensionen den Wert drei. Die VC-Dimension bietet ein Maß für die Ausdruckskraft eines Modells: Eine höhere VC-Dimension deutet auf ein flexibleres Modell hin, das komplexere Muster anpassen kann, erhöht jedoch auch das Risiko von Overfitting.
In der binären Klassifikation spielt die VC-Dimension eine entscheidende Rolle beim Verständnis des Trade-offs zwischen Modellkomplexität und Generalisierung. Nach der Theorie gilt, wenn die VC-Dimension im Verhältnis zur Anzahl der Trainingsproben zu hoch ist, kann das Modell die Trainingsdaten perfekt anpassen, jedoch versagen, auf ungesehene Daten zu generalisieren. Umgekehrt kann ein Modell mit einer niedrigen VC-Dimension unteranpassen, weil es wichtige Muster in den Daten nicht erfasst. Die VC-Dimension bietet somit theoretische Garantien über den Generalisierungsfehler, wie sie in der VC-Ungleichung und verwandten Grenzen formalisiert sind.
Das Konzept der VC-Dimension ist zentral für die Entwicklung von Lernalgorithmen und die Analyse ihrer Leistung. Es bildet die Grundlage für das Probably Approximately Correct (PAC) Lernrahmenwerk, das die Bedingungen charakterisiert, unter denen ein Lernalgorithmus mit hoher Wahrscheinlichkeit einen niedrigen Generalisierungsfehler erzielen kann. Die VC-Dimension wird auch im Design und in der Analyse von Support Vector Machines (SVMs) verwendet, einer weit verbreiteten Klasse von binären Klassifizierern, sowie in der Untersuchung von neuronalen Netzwerken und anderen Modellen des maschinellen Lernens.
Die Bedeutung der VC-Dimension in der binären Klassifikation wird von führenden Forschungsinstitutionen und Organisationen im Bereich der künstlichen Intelligenz und des maschinellen Lernens anerkannt, wie der Association for the Advancement of Artificial Intelligence und der Association for Computing Machinery. Diese Organisationen unterstützen die Forschung und die Verbreitung grundlegender Konzepte wie die VC-Dimension, die weiterhin die theoretischen Grundlagen und praktischen Anwendungen des maschinellen Lernens prägen.
Shattering, Wachstumsfunktionen und deren Bedeutung
Die Konzepte von Shattering und Wachstumsfunktionen sind zentral für das Verständnis der Vapnik–Chervonenkis (VC) Dimension, einem grundlegenden Maß in der Theorie des statistischen Lernens. Die VC-Dimension, eingeführt von Vladimir Vapnik und Alexey Chervonenkis, quantifiziert die Kapazität einer Funktionensammlung (Hypothesenklasse), um Daten anzupassen, und ist entscheidend für die Analyse der Generalisierungsfähigkeit von Lernalgorithmen.
Shattering bezieht sich auf die Fähigkeit einer Hypothesenklasse, alle möglichen Kennzeichnungen eines endlichen Satzes von Punkten perfekt zu klassifizieren. Formal wird eine Menge von Punkten als von einer Hypothesenklasse zertrümmert angesehen, wenn für jede mögliche Zuordnung binärer Labels zu den Punkten eine Funktion in der Klasse existiert, die die Punkte gemäß diesen Labels korrekt trennt. Zum Beispiel kann im Fall linearer Klassifizierer in zwei Dimensionen jede Menge von drei nicht kollinearen Punkten zertrümmert werden, jedoch nicht alle Mengen von vier Punkten.
Die Wachstumsfunktion, auch bekannt als der Shatter-Koeffizient, misst die maximale Anzahl von unterschiedlichen Kennzeichnungen (Dichotomien), die eine Hypothesenklasse auf einer Menge von n Punkten realisieren kann. Wenn die Hypothesenklasse jede Menge von n Punkten zertrümmern kann, entspricht die Wachstumsfunktion 2n. Wenn n zunimmt, erreichen die meisten Hypothesenklassen einen Punkt, an dem sie nicht mehr alle möglichen Kennzeichnungen zertrümmern können, und die Wachstumsfunktion wächst langsamer. Die VC-Dimension ist als die größte ganze Zahl d definiert, für die die Wachstumsfunktion 2d entspricht; mit anderen Worten, sie ist die Größe der größten Menge, die von der Hypothesenklasse zertrümmert werden kann.
Diese Konzepte sind bedeutend, weil sie einen rigorosen Weg bieten, um die Komplexität und Ausdruckskraft von Lernmodellen zu analysieren. Eine höhere VC-Dimension deutet auf ein ausdrucksstärkeres Modell hin, das komplexere Muster anpassen kann, jedoch auch ein höheres Risiko für Overfitting mit sich bringt. Umgekehrt deutet eine niedrige VC-Dimension auf ein begrenztes Kapazität hin, was zu Underfitting führen kann. Die VC-Dimension steht direkt im Zusammenhang mit Generalisierungsgrenzen: Sie hilft dabei zu bestimmen, wie viele Trainingsdaten benötigt werden, um sicherzustellen, dass die Leistung des Modells auf ungesehenen Daten nahe der Leistung auf dem Trainingssatz liegt. Diese Beziehung wird in Theoremen wie dem fundamentalen Theorem des statistischen Lernens formalisiert, das einen Großteil der modernen Theorie des maschinellen Lernens untermauert.
Die Erforschung von Shattering und Wachstumsfunktionen sowie deren Verbindung zur VC-Dimension ist grundlegend in der Arbeit von Organisationen wie der Association for the Advancement of Artificial Intelligence und dem Institute of Mathematical Statistics, die die Forschung und Verbreitung von Fortschritten in der Theorie des statistischen Lernens und deren Anwendungen fördern.
VC-Dimension und Modellkapazität: Praktische Implikationen
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das ein rigoroses Maß für die Kapazität oder Komplexität einer Gruppe von Funktionen (Hypothesenklasse) bietet, die ein maschinelles Lernmodell implementieren kann. In praktischen Begriffen quantifiziert die VC-Dimension die größte Anzahl von Punkten, die zertrümmert werden können (d.h. in allen möglichen Varianten korrekt klassifiziert) von dem Modell. Dieses Maß ist entscheidend für das Verständnis des Trade-offs zwischen der Fähigkeit eines Modells, Trainingsdaten anzupassen, und seiner Fähigkeit, auf ungesehene Daten zu generalisieren.
Eine höhere VC-Dimension deutet auf eine ausdrucksstärkere Modellklasse hin, die in der Lage ist, komplexere Muster darzustellen. Zum Beispiel hat ein linearer Klassifizierer in einem zweidimensionalen Raum eine VC-Dimension von 3, was bedeutet, dass er jede Menge von drei Punkten zertrümmern kann, aber nicht alle Mengen von vier. Im Gegensatz dazu können komplexere Modelle, wie neuronale Netzwerke mit vielen Parametern, viel höhere VC-Dimensionen haben, was ihre größere Kapazität widerspiegelt, unterschiedliche Datensätze anzupassen.
Die praktischen Implikationen der VC-Dimension treten am deutlichsten im Kontext von Overfitting und Underfitting zutage. Wenn die VC-Dimension eines Modells viel größer ist als die Anzahl der Trainingsproben, könnte das Modell überanpassen, indem es die Trainingsdaten auswendig lernt, anstatt verallgemeinerbare Muster zu lernen. Umgekehrt könnte ein Modell mit einer zu niedrigen VC-Dimension unteranpassen und wichtige Strukturen in den Daten nicht erfassen. Daher ist die Auswahl eines Modells mit einer angemessenen VC-Dimension im Verhältnis zur Datensatzgröße entscheidend, um eine gute Generalisierungsleistung zu erzielen.
Die VC-Dimension bildet auch die Grundlage für theoretische Garantien in der Lerntheorie, wie im Probably Approximately Correct (PAC) Lernrahmenwerk. Sie bietet Grenzen für die Anzahl der Trainingsproben, die erforderlich sind, um sicherzustellen, dass das empirische Risiko (Fehler im Trainingssatz) nahe am wahren Risiko (erwarteter Fehler bei neuen Daten) liegt. Diese Ergebnisse helfen Praktikern, die Stichprobenkomplexität zu schätzen, die für zuverlässiges Lernen erforderlich ist, insbesondere in risikobehafteten Anwendungen wie medizinischen Diagnosen oder autonomen Systemen.
In der Praxis, während die genaue VC-Dimension oft schwierig zu berechnen ist für komplexe Modelle, informiert ihre konzeptionelle Rolle das Design und die Auswahl von Algorithmen. Regularisierungstechniken, Kriterien zur Modellselektion und Kreuzvalidierungsstrategien werden alle von den zugrunde liegenden Prinzipien der Kapazitätskontrolle beeinflusst, die durch die VC-Dimension formuliert sind. Das Konzept wurde von Vladimir Vapnik und Alexey Chervonenkis eingeführt, deren Arbeit die Grundlage für die moderne Theorie des statistischen Lernens legte und weiterhin Forschung und Anwendungen im maschinellen Lernen beeinflusst (Institute of Mathematical Statistics).
Verbindungen zu Overfitting und Generalisierungsgrenzen
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das unser Verständnis von Overfitting und Generalisierung in maschinellen Lernmodellen direkt beeinflusst. Die VC-Dimension quantifiziert die Kapazität oder Komplexität einer Gruppe von Funktionen (Hypothesenklasse), indem sie die größte Menge von Punkten misst, die zertrümmert werden kann – d.h. in allen möglichen Varianten korrekt klassifiziert – von den Funktionen in der Klasse. Dieses Maß ist entscheidend für die Analyse, wie gut ein Modell, das auf einer endlichen Datenmenge trainiert wurde, auf ungesehene Daten abschneiden wird, eine Eigenschaft, die als Generalisierung bekannt ist.
Overfitting tritt auf, wenn ein Modell nicht nur die zugrunde liegenden Muster lernt, sondern auch das Rauschen in den Trainingsdaten, was zu schlechten Leistungen bei neuen, ungesehenen Daten führt. Die VC-Dimension bietet einen theoretischen Rahmen, um Overfitting zu verstehen und zu mildern. Wenn die VC-Dimension einer Hypothesenklasse viel größer ist als die Anzahl der Trainingsproben, hat das Modell ausreichend Kapazität, um zufälliges Rauschen anzupassen, was das Risiko des Overfittings erhöht. Umgekehrt kann ein Modell, dessen VC-Dimension zu niedrig ist, unteranpassen und es versäumen, die wesentlichen Strukturen der Daten zu erfassen.
Die Beziehung zwischen VC-Dimension und Generalisierung wird durch Generalisierungsgrenzen formalisiert. Diese Grenzen, wie sie aus den grundlegenden Arbeiten von Vladimir Vapnik und Alexey Chervonenkis abgeleitet wurden, besagen, dass mit hoher Wahrscheinlichkeit die Differenz zwischen dem empirischen Risiko (Fehler im Trainingssatz) und dem wahren Risiko (erwarteter Fehler bei neuen Daten) klein ist, sofern die Anzahl der Trainingsproben relativ zur VC-Dimension ausreichend groß ist. Insbesondere nimmt der Generalisierungsfehler ab, je mehr Proben vorhanden sind, vorausgesetzt, die VC-Dimension bleibt konstant. Diese Einsicht untermauert das Prinzip, dass komplexere Modelle (mit höherer VC-Dimension) mehr Daten benötigen, um gut zu generalisieren.
- Die VC-Dimension steht im Zentrum der Theorie der einheitlichen Konvergenz, die sicherstellt, dass empirische Durchschnitte gleichmäßig über alle Funktionen in der Hypothesenklasse zu erwarteten Werten konvergieren. Diese Eigenschaft ist für die Garantie entscheidend, dass die Minimierung des Fehlers im Trainingssatz zu einem niedrigen Fehler bei ungesehenen Daten führt.
- Das Konzept ist auch integraler Bestandteil der Entwicklung der strukturellen Risiko-Minimierung, einer Strategie, die Modellkomplexität und Trainingsfehler ausgleicht, um eine optimale Generalisierung zu erreichen, wie sie in der Theorie von Support Vector Machines und anderen Lernalgorithmen formalisiert ist.
Die Bedeutung der VC-Dimension im Verständnis von Overfitting und Generalisierung wird von führenden Forschungsinstituten anerkannt und ist grundlegend im Lehrplan der Theorie des statistischen Lernens, wie sie von Organisationen wie dem Institute for Advanced Study und der Association for the Advancement of Artificial Intelligence umrissen wird. Diese Organisationen tragen zur laufenden Entwicklung und Verbreitung theoretischer Fortschritte im maschinellen Lernen bei.
VC-Dimension in realen maschinellen Lernalgorithmen
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das ein rigoroses Maß für die Kapazität oder Komplexität einer Menge von Funktionen (Hypothesenklasse) bietet, die ein maschinelles Lernalgorithmus implementieren kann. Im realen maschinellen Lernen spielt die VC-Dimension eine entscheidende Rolle beim Verständnis der Generalisierungsfähigkeit von Algorithmen – wie gut ein Modell, das auf einer endlichen Probe trainiert wurde, voraussichtlich auf ungesehene Daten abschneiden wird.
In praktischen Begriffen hilft die VC-Dimension, den Trade-off zwischen Modellkomplexität und Risiko des Overfittings zu quantifizieren. Zum Beispiel hat ein linearer Klassifizierer in einem zweidimensionalen Raum (wie ein Perzeptron) eine VC-Dimension von 3, was bedeutet, dass er jede Menge von drei Punkten zertrümmern kann, aber nicht alle Mengen von vier. Komplexere Modelle, wie neuronale Netzwerke, können viel höhere VC-Dimensionen haben, was ihre Fähigkeit widerspiegelt, kompliziertere Muster in Daten anzupassen. Ein höherer VC-Dimension erhöht jedoch auch das Risiko des Overfittings, bei dem das Modell Rauschen anstelle der zugrunde liegenden Struktur erfasst.
Die VC-Dimension ist besonders relevant im Kontext des Probably Approximately Correct (PAC) Lernrahmenwerks, das theoretische Garantien für die Anzahl der erforderlichen Trainingsproben bietet, um ein gewünschtes Genauigkeits- und Vertrauensniveau zu erreichen. Nach der Theorie wächst die Stichprobenkomplexität – die erforderliche Anzahl von Beispielen für das Lernen – mit der VC-Dimension der Hypothesenklasse. Diese Beziehung leitet Praktiker bei der Auswahl geeigneter Modellklassen und Regularisierungsstrategien, um Ausdruckskraft und Generalisierung auszubalancieren.
In der Praxis informiert die VC-Dimension das Design und die Bewertung von Algorithmen wie Support Vector Machines (SVMs), Entscheidungsbäumen und neuronalen Netzwerken. Beispielsweise sind SVMs eng mit der VC-Theorie verbunden, da ihr Prinzip der Margenmaximierung als eine Möglichkeit interpretiert werden kann, die effektive VC-Dimension des Klassifizierers zu kontrollieren und damit die Generalisierungsleistung zu verbessern. Ähnlich können Beschneidungstechniken in Entscheidungsbäumen als Methoden betrachtet werden, die VC-Dimension zu reduzieren und Overfitting zu mildern.
Obwohl die genaue VC-Dimension komplexer Modelle wie tiefer neuronaler Netzwerke oft schwer zu berechnen ist, bleibt das Konzept einflussreich bei der Führung von Forschung und Praxis. Es bildet die Grundlage für die Entwicklung von Regularisierungsmethoden, Kriterien zur Modellselektion und theoretische Grenzen der Lernleistung. Die anhaltende Relevanz der VC-Dimension spiegelt sich in ihrer grundlegenden Rolle in der Arbeit von Organisationen wie der Association for the Advancement of Artificial Intelligence und der Association for Computing Machinery wider, die die Forschung in der Theorie des maschinellen Lernens und deren praktischen Implikationen fördern.
Einschränkungen und Kritiken der VC-Dimension
Die Vapnik–Chervonenkis (VC) Dimension ist ein grundlegendes Konzept in der Theorie des statistischen Lernens, das ein Maß für die Kapazität oder Komplexität einer Gruppe von Funktionen (Hypothesenklasse) in Bezug auf ihre Fähigkeit darstellt, Datenpunkte zu zertrümmern. Trotz ihrer theoretischen Bedeutung hat die VC-Dimension mehrere bemerkenswerte Einschränkungen und wurde innerhalb der Maschinenlern- und Statistikgemeinschaftes verschieden kritisiert.
Eine wesentliche Einschränkung der VC-Dimension ist ihr Fokus auf die schlechtesten Fälle. Die VC-Dimension quantifiziert die größte Menge von Punkten, die von einer Hypothesenklasse zertrümmert werden kann, aber dies spiegelt nicht immer die typische oder durchschnittliche Leistung von Lernalgorithmen in praktischen Anwendungen wider. Das Ergebnis ist, dass die VC-Dimension oft die tatsächliche Komplexität überschätzen kann, die für eine erfolgreiche Generalisierung in realen Daten erforderlich ist, wo Verteilungen oft weit von adversarialen oder schlechtesten Fällen entfernt sind. Diese Diskrepanz kann zu übermäßig pessimistischen Grenzen der Stichprobenkomplexität und des Generalisierungsfehlers führen.
Eine weitere Kritik betrifft die Anwendbarkeit der VC-Dimension auf moderne maschinelle Lernmodelle, insbesondere tiefe neuronale Netzwerke. Während die VC-Dimension gut definiert ist für einfache Hypothesenklassen wie lineare Klassifizierer oder Entscheidungsbäume, wird es schwierig, sie für hochparametrisierte Modelle zu berechnen oder sogar sinnvoll zu interpretieren. In vielen Fällen können tiefe Netzwerke extrem hohe oder gar unendliche VC-Dimensionen haben und dennoch in der Praxis gut generalisieren. Phänomene, die manchmal als „Generalizationsparadox“ bezeichnet werden, deuten darauf hin, dass die VC-Dimension nicht alle Faktoren vollständig erfasst, die die Generalisierung in zeitgenössischen maschinellen Lernsystemen bestimmen.
Darüber hinaus ist die VC-Dimension von Natur aus ein kombinatorisches Maß, das die Geometrie und Struktur der Datenverteilung ignoriert. Sie berücksichtigt keine margenbasierten Eigenschaften, Regularisierung oder andere algorithmische Techniken, die die Generalisierung erheblich beeinflussen können. Alternative Maßzahlen zur Komplexität, wie Rademacher-Komplexität oder Überdeckungszahlen, wurden vorgeschlagen, um einige dieser Mängel zu beheben, indem sie databhängige oder geometrische Aspekte integrieren.
Schließlich geht die VC-Dimension von der Annahme aus, dass Datenpunkte unabhängig und identisch verteilt (i.i.d.) sind, ein Ansatz, der in vielen realen Anwendungen, wie Zeitreihenanalysen oder strukturierten Vorhersageaufgaben, möglicherweise nicht zutrifft. Dies schränkt die direkte Anwendbarkeit der VC-basierten Theorie in bestimmten Bereichen weiter ein.
Trotz dieser Einschränkungen bleibt die VC-Dimension ein Eckpfeiler der Lerntheorie und bietet wertvolle Einsichten in die grundlegenden Grenzen der Erlernbarkeit. Laufende Forschungen von Organisationen wie der Association for the Advancement of Artificial Intelligence und dem Institute of Mathematical Statistics untersuchen weiterhin Erweiterungen und Alternativen zum VC-Rahmenwerk, um theoretische Garantien besser mit empirischen Beobachtungen im modernen maschinellen Lernen in Einklang zu bringen.
Zukünftige Richtungen und offene Probleme in der VC-Theorie
Die Vapnik–Chervonenkis (VC) Dimension bleibt ein Eckpfeiler der Theorie des statistischen Lernens und bietet ein rigoroses Maß für die Kapazität von Hypothesenklassen und deren Fähigkeit, aus endlichen Proben zu generalisieren. Trotz ihrer grundlegenden Rolle treiben mehrere zukünftige Richtungen und offene Probleme weiterhin die Forschung in der VC-Theorie voran, die sowohl theoretische Herausforderungen als auch praktische Anforderungen im modernen maschinellen Lernen widerspiegeln.
Eine prominente Richtung ist die Erweiterung der VC-Theorie auf komplexere und strukturierte Datenbereiche. Die traditionelle Analyse der VC-Dimension ist gut geeignet für binäre Klassifikation und einfache Hypothesenräume, aber moderne Anwendungen umfassen häufig Mehrklassen-, strukturierte Ausgaben oder Daten mit komplexen Abhängigkeiten. Die Entwicklung allgemein gehaltener Begriffe der VC-Dimension, die in der Lage sind, die Komplexität tiefer neuronaler Netzwerke, rekurrenter Architekturen und anderer fortgeschrittener Modelle zu erfassen, bleibt eine offene Herausforderung. Dazu gehört das Verständnis der effektiven Kapazität dieser Modelle und wie sie sich auf deren empirische Leistung und Generalisierungsfähigkeit auswirkt.
Ein weiteres aktives Forschungsfeld ist der rechnerische Aspekt der VC-Dimension. Während die VC-Dimension theoretische Garantien bietet, ist das Berechnen oder auch nur das Approximieren der VC-Dimension für beliebige Hypothesenklassen oft unpraktisch. Effiziente Algorithmen zur Schätzung der VC-Dimension, insbesondere für großflächige oder hochdimensionale Modelle, sind sehr gefragt. Dies hat Auswirkungen auf die Modellauswahl, Regularisierung und das Design von Lernalgorithmen, die adaptiv die Modellkomplexität steuern können.
Die Beziehung zwischen der VC-Dimension und anderen Komplexitätsmaßen, wie Rademacher-Komplexität, Überdeckungszahlen und algorithmischer Stabilität, bietet ebenfalls fruchtbaren Boden für die Erkundung. Während maschinelle Lernmodelle zunehmend ausgefeilt werden, ist das Verständnis davon, wie diese unterschiedlichen Maße interagieren und welche am aussagekräftigsten in der Praxis sind, ein zentrales offenes Problem. Dies ist besonders relevant im Kontext von überparametrisierten Modellen, bei denen die klassische VC-Theorie möglicherweise nicht vollständig beobachtete Generalisierungsphänomene erklären kann.
Darüber hinaus führen die neuen Entwicklungen im Bereich Datenschutz und Fairness zu neuen Dimensionen in der VC-Theorie. Forscher untersuchen, wie Einschränkungen wie Differentialprivatsphäre oder Fairnessanforderungen die VC-Dimension beeinflussen und somit die Erlernbarkeit von Hypothesenklassen unter diesen Einschränkungen beeinflussen. Diese Schnittstelle zwischen VC-Theorie und ethischen sowie rechtlichen Überlegungen wird voraussichtlich an Bedeutung gewinnen, da maschinelle Lernsysteme zunehmend in sensiblen Bereichen eingesetzt werden.
Schließlich wirft die fortlaufende Entwicklung der Quantencomputing-Technologien und deren potenzielle Anwendungen im maschinellen Lernen Fragen zur VC-Dimension in quantenhypothetischen Räumen auf. Das Verständnis, wie quantenmechanische Ressourcen die Kapazität und Generalisierung von Lernalgorithmen beeinflussen, ist ein aufkommendes Gebiet theoretischer Forschung.
Während sich das Feld weiterentwickelt, unterstützen Organisationen wie die Association for the Advancement of Artificial Intelligence und das Institute of Mathematical Statistics weiterhin die Forschung und Verbreitung von Fortschritten in der VC-Theorie und stellen sicher, dass grundlegende Fragen im Vordergrund der Forschung im maschinellen Lernen bleiben.
Quellen & Referenzen