Vapnik–Chervonenkis-ulottuvuuden purkaminen: Avain mallin monimutkaisuuden ja yleistämisen ymmärtämiseen koneoppimisessa. Opi, kuinka VC-ulottuvuus muokkaa algoritmien oppimisen rajoja.
- Johdanto Vapnik–Chervonenkis-ulottuvuuteen
- Historialliset alkuperät ja teoreettiset perusteet
- Matemaattinen määritelmä ja kehys
- VC-ulottuvuus binäärisessä luokittelussa
- Shattering, kasvufunktiot ja niiden merkitys
- VC-ulottuvuus ja mallin kapasiteetti: Käytännön merkitys
- Yhteydet yliopettamiseen ja yleistämisen rajoihin
- VC-ulottuvuus todellisten koneoppimisalgoritmien yhteydessä
- VC-ulottuvuuden rajoitukset ja kritiikki
- Tulevaisuuden suuntaukset ja avoimet ongelmat VC-teoriassa
- Lähteet ja viitteet
Johdanto Vapnik–Chervonenkis-ulottuvuuteen
Vapnik–Chervonenkis-ulottuvuus (VC-ulottuvuus) on keskeinen käsite tilastollisessa oppimisteoriassa, jonka ovat esittäneet Vladimir Vapnik ja Alexey Chervonenkis 1970-luvun alussa. Se tarjoaa tiukan matemaattisen kehyksen funktiojoukon (hypoteesiluokan) kapasiteetin tai monimutkaisuuden kvantifioimiseksi sen kyvyssä luokitella datapisteitä. VC-ulottuvuus määritellään suurimpana pistemääränä, joka voidaan shatteroida (eli luokitella oikein kaikilla mahdollisilla tavoilla) hypoteesiluokan avulla. Tämä käsite on keskeinen oppimisalgoritmien yleistämiskyvyn ymmärtämisessä, koska se yhdistää mallin ilmaisukyvyn sen riskiin ylinjuuttumisesta.
Virallisemmissa termeissä, jos hypoteesiluokka voi shatteroida joukon n pistettä, mutta ei voi shatteroida mitään joukkoa n+1 pistettä, niin sen VC-ulottuvuus on n. Esimerkiksi kahden ulottuvuuden lineaaristen luokittajien luokalla on VC-ulottuvuus 3, mikä tarkoittaa, että se voi shatteroida minkä tahansa kolmen pisteen joukon, mutta ei kaikkia neljän pisteen joukkoja. VC-ulottuvuus toimii näin mittarina hypoteesiluokan rikkaudelle, riippumatta tiettyjen datanjakautumista.
VC-ulottuvuuden tärkeys piilee sen roolissa teoreettisten takuiden tarjoamisessa koneoppimisalgoritmeille. Se on keskeinen komponentti yleistymisvirheen rajojen derivoinnissa, joka on ero koulutusdatassa ja odotetussa virheessä näkymättömässä datassa. Kuuluisan VC-epäyhtälön, esimerkiksi, liittyy VC-ulottuvuus empiiriseen riskiin (koulutusero) ja todelliseen riskiin (yleistämisvirhe). Tämä suhde on keskeinen rakenteellisen riskin minimoinnin periaatteessa, joka on modernin tilastollisen oppimisteorian kulmakivi, ja jonka tavoitteena on tasapainottaa mallin monimutkaisuus ja koulutusvirhe optimaalisen yleistämisen saavuttamiseksi.
VC-ulottuvuuden käsite on laajasti omaksuttu erilaisten oppimisalgoritmien analyysissä, mukaan lukien tuki-vektori-koneet, neuroverkot ja päätöspuut. Se on myös perustavanlaatuinen Oletettavasti Luultavasti Oikein (PAC) oppimiskehyksessä, joka formaloi olosuhteet, joissa oppimisalgoritmin voidaan odottaa toimivan hyvin. Teoreettiset perusteet, joita VC-ulottuvuus tarjoaa, ovat olleet keskeisiä koneoppimisen alalla, ja niitä tunnustavat johtavat tutkimuslaitokset, kuten Institute for Advanced Study ja Association for the Advancement of Artificial Intelligence.
Historialliset alkuperät ja teoreettiset perusteet
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, jonka ovat esittäneet 1970-luvun alussa Vladimir Vapnik ja Alexey Chervonenkis. Heidän pioneerityönsä syntyi Venäjän tiedeakatemian ohjauksen tieteellisen instituutin yhteydessä, jossa he pyrkivät formalisoimaan kaavan tunnistamisen ja koneoppimisen taustaperiaatteita. VC-ulottuvuus tarjoaa tiukan matemaattisen kehyksen funktiojoukon (hypoteesiluokka) kyvyn kvantifioimiseksi sovittaa dataa, mikä on ratkaisevaa oppimisalgoritmien yleistymiskyvyn ymmärtämisessä.
VC-ulottuvuuden ydin mittaa suurinta pistemäärää, joka voidaan shatteroida (eli luokitella oikein kaikilla mahdollisilla tavoilla) hypoteesiluokan avulla. Jos funktioluokka voi shatteroida kooltaan d olevan joukon mutta ei d+1-kokoista, sen VC-ulottuvuus on d. Tämä käsite mahdollistaa tutkijoiden analysoida mallin monimutkaisuuden ja ylinjuuttumisriskin välisiä kauppasuhteita, jotka ovat keskeisiä kysymyksiä koneoppimisessa. VC-ulottuvuuden käyttöönotto merkitsi merkittävää edistystä aikaisempiin, vähemmän formaaleihin oppimisteorioihin verrattuna, tarjoamalla sillan empiirisen suorituskyvyn ja teoreettisten takuuten välillä.
VC-ulottuvuuden teoreettiset perusteet liittyvät tiiviisti Oletettavasti Luultavasti Oikein (PAC) -oppimiskehyksen kehittämiseen, joka formaloi olosuhteet, joissa oppimisalgoritmin voidaan odottaa toimivan hyvin näkymättömässä datassa. VC-ulottuvuus toimii keskeisenä parametrina teoreemoissa, jotka rajoittavat luokittajien yleistymisvirhettä, todistaen, että äärellinen VC-ulottuvuus on tarpeellinen PAC-oppimismallin oppimiskelpoisuudelle. Tämä näkemys on vaikuttanut syvästi algoritmien suunnitteluun ja analyysiin tietojenkäsittelyn alalla luonnollisesta kielestä tietokonenäköön.
Vapnikin ja Chervonenkisin työ loi perustan tukivektorikoneiden ja muiden ydinperusteisten menetelmien kehittämiselle, jotka perustuvat kapasiteetin hallinnan ja rakenteellisen riskin minimoinnin periaatteisiin. Heidän panoksensa on tunnustettu johtavilla tieteellisillä organisaatioilla, ja VC-ulottuvuus on edelleen keskeinen aihe edistyneissä koneoppimis- ja tilastokursseissa ympäri maailmaa. American Mathematical Society ja Association for the Advancement of Artificial Intelligence ovat organisaatioita, jotka ovat korostaneet näiden teoreettisten edistysten merkitystä julkaisuissaan ja konferensseissaan.
Matemaattinen määritelmä ja kehys
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, tarjoten tiukan mittauksen joukon funktioiden (hypoteesiluokka) kapasiteetista tai monimutkaisuudesta sen kyvyssä luokitella datapisteitä. Virallisesti VC-ulottuvuus määritellään indikaattorifunktioiden (tai joukkojen) luokalle suurimpana pistemääränä, joka voidaan shatteroida luokan avulla. ”Shatteroida” tarkoittaa joukkoa pisteitä siten, että jokaiselle mahdolliselle merkinnälle näille pisteille on olemassa funktio luokassa, joka oikein määrittää nämä merkinnät.
Olkoon H hypoteesiluokka binaarista arvoa omaavia funktioita, jotka kartottavat syöteavaruudesta X joukkoon {0,1}. Pistejoukko S = {x₁, x₂, …, xₙ} sanotaan shatteroituneeksi H:n toimesta, jos jokaiselle mahdolliselle osajoukolle A joukosta S on olemassa funktio h ∈ H, niin että h(x) = 1</i} jos ja vain jos x ∈ A. Hypoteesiluokan H VC-ulottuvuus, merkittynä VC(H), on suurin kardinaliteetti n, jolle on olemassa joukko n pistettä X:ssä, joka on shatteroitunut H:n toimesta. Jos satunnaisesti suuret äärelliset joukot voidaan shatteroida, VC-ulottuvuus on äärettömän suuri.
Matemaattisesti VC-ulottuvuus tarjoaa sillan hypoteesiluokan ilmaisukyvyn ja sen yleistämiskyvyn välillä. Korkeampi VC-ulottuvuus tarkoittaa ilmaisumahdollisuudeltaan rikkaampaa luokkaa, kykyä sovittaa monimutkaisempia kuvioita, mutta myös suurempaa riskiä ylinjuuttumisesta. Päinvastoin, matalampi VC-ulottuvuus viittaa rajoitettuun ilmaisukykyyn ja mahdollisesti parempaan yleistämiseen, mutta mahdollisesti yli-alimääräisesti. VC-ulottuvuus on keskeinen työkalu yleistämisen rajoiden derivoinnissa, kuten todisteissa, jotka on formalisoitu tilastollisen oppimisteorian perustavanlaatuisissa teoreemoissa, jotka liittävät VC-ulottuvuuden opastusvaatimuksiin kiinteästi.
Käsite esiteltiin Vladimir Vapnikin ja Alexey Chervonenkisin toimesta 1970-luvulla, ja se on teoreettisen analyysin perusta oppimisalgoritmeille, kuten tukivektori koneille ja empiiriselle riskin minimoinnille. VC-ulottuvuus on laajasti tunnustettu ja käytetty koneoppimisen kentällä, ja siitä keskustellaan yksityiskohtaisesti organisaatioissa, kuten Institute of Mathematical Statistics ja Association for the Advancement of Artificial Intelligence, jotka ovat johtavia auktoriteetteja tilastollisessa ja tekoälytutkimuksessa.
VC-ulottuvuus binäärisessä luokittelussa
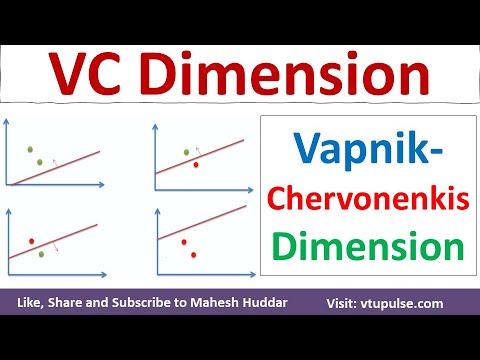
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, erityisesti merkityksellinen binääristen luokitusmallien analysoinnissa. Vladimir Vapnikin ja Alexey Chervonenkisin 1970-luvun alussa esittämä VC-ulottuvuus kvantifioi joukon funktioiden (hypoteesiluokka) kapasiteetin tai monimutkaisuuden mittaamalla sen kyvyn shatteroida äärelliset datapistejoukot. Binäärisessä luokittelussa ”shattering” viittaa luokittajan kykyyn merkitä kaikki mahdolliset binääristä merkintää (0 tai 1) valitut pisteet.
Virallisesti hypoteesiluokan VC-ulottuvuus on suurin pistemäärä, joka voidaan shatteroida kyseisellä luokalla. Esimerkiksi, harkitse kahden ulottuvuuden lineaaristen luokittajien luokkaa (perceptron). Tämä luokka voi shatteroida minkä tahansa kolmen pisteen joukon, mutta ei kaikkia neljän pisteen joukoja. Siksi kahden ulottuvuuden lineaaristen luokittajien VC-ulottuvuus on kolme. VC-ulottuvuus tarjoaa mittarin mallin ilmaisukyvylle: korkeampi VC-ulottuvuus tarkoittaa joustavampaa mallia, joka voi sovittaa monimutkaisempia kuvioita, mutta lisää myös ylinjuuttamisen riskiä.
Binäärisessä luokittelussa VC-ulottuvuudella on keskeinen rooli mallin monimutkaisuuden ja yleistämisen kauppasuhteiden ymmärtämisessä. Teorian mukaan, jos VC-ulottuvuus on liian korkea suhteessa koulutusnäytteen määrään, malli saattaa sovittaa koulutusdataa täydellisesti, mutta epäonnistua yleistämään näkymättömään dataan. Vastaan, malli, jossa on alhainen VC-ulottuvuus, saattaa alimäärätä, eikä pystytä vangitsemaan datan tärkeitä kuvioita. Näin ollen VC-ulottuvuus tarjoaa teoreettisia taustatakuuksia yleistämisvirheelle, kuten formalisoidun VC-epäyhtälön ja siihen liittyvät rajat.
VC-ulottuvuuden käsite on keskeinen oppimisalgoritmien kehittämisessä ja niiden suorituskyvyn analysoinnissa. Se tukee Oletettavasti Luultavasti Oikein (PAC) -oppimiskehyksen toimintaa, joka luonnehtii olosuhteita, joissa oppimisalgoritmi voi saavuttaa matalan yleistämisvirheen suurella todennäköisyydellä. VC-ulottuvuus on myös käytetty tukivektorikoneiden (SVM) suunnittelussa ja analysoinnissa, joka on laajasti käytetty binääriluokittajaluokka, sekä neuroverkkoin ja muiden koneoppimismallien tutkimisessa.
VC-ulottuvuuden tärkeys binäärisessä luokittelussa tunnustavat johtavat tutkimuslaitokset ja organisaatiot tekoälyn ja koneoppimisen alalla, kuten Association for the Advancement of Artificial Intelligence ja Association for Computing Machinery. Nämä organisaatiot tukevat perustavanlaatuisten käsitteiden, kuten VC-ulottuvuuden, tutkimusta ja levittämistä, jotka jatkavat teoreettisten perusteiden ja käytännön sovellusten muovaamista koneoppimisessa.
Shattering, kasvufunktiot ja niiden merkitys
Shattering ja kasvufunktiot ovat keskeisiä käsitteitä Vapnik–Chervonenkis (VC) -ulottuvuuden ymmärtämisessä, joka on perustavanlaatuinen mitta tilastollisessa oppimisteoriassa. VC-ulottuvuus, jonka ovat esitelleet Vladimir Vapnik ja Alexey Chervonenkis, kvantifioi joukon funktioiden (hypoteesiluokka) kapasiteetin sovittaa dataa ja on tärkeä oppimisalgoritmien yleistämiskyvyn analysoinnissa.
Shattering viittaa hypoteesiluokan kykyyn luokitella kaikki mahdolliset merkinnät tietystä äärellisten pisteiden joukosta. Virallisesti joukkoa pisteitä sanotaan shatteroituneeksi hypoteesiluokan toimesta, jos jokaiselle mahdolliselle binaaristen merkintöjen asettelulle näille pisteille on olemassa luokassa funktio, joka oikein erottaa pisteet niiden merkintöjen mukaan. Esimerkiksi lineaaristen luokittajien tapauksessa kahdessa ulottuvuudessa mikä tahansa kolmonen ei-kollineaarista pistettä voidaan shatteroida, mutta ei kaikkia neljän pisteen joukkoja.
Kasvufunktio, myös tunnettu shatter-kertoimena, mittaa erilaisten merkintöjen (dichotomies) enimmäismäärän, jotka hypoteesiluokka voi toteuttaa kenellekään n-pisteen joukolle. Jos hypoteesiluokka voi shatteroida jokaisen n-pisteen joukon, kasvufunktio on yhtä suuri kuin 2n. Kuitenkin, kun n kasvaa, useimmat hypoteesiluokat saavuttavat pisteen, jossa ne eivät voi enää shatteroida kaikkia mahdollisia merkintöjä, ja kasvufunktio kasvaa hitaammin. VC-ulottuvuus määritellään suurimmaksi kokonaisluvuksi d siten, että kasvufunktio on yhtä suuri kuin 2d; toisin sanoen se on suurin joukko, joka voidaan shatteroida hypoteesiluokan avulla.
Nämä käsitteet ovat merkittäviä, koska ne tarjoavat tiukan tavan analysoida oppimismallien kompleksisuutta ja ilmaisukyvyn voimaa. Korkeampi VC-ulottuvuus osoittaa ilmaisummaltaan rikkaampaa mallia, joka kykenee sovittamaan monimutkaisempia kuvioita, mutta myös suuremmalla riskillä ylinjuuttamisesta. Käänteisesti matalampi VC-ulottuvuus viittaa rajoitettuun kapasiteettiin, joka voi johtaa alimääritykseen. VC-ulottuvuus on suoraan kytköksissä yleistymisen rajoihin: se auttaa määrittämään kuinka paljon koulutusdataa tarvitaan varmistamaan, että mallin suorituskyky näkymättömässä datassa on lähellä sen suorituskykyä koulutusaineistossa. Tämä suhde on formalisoitu teoreemoissa, kuten tilastollisen oppimisen perustavanlaatuisissa teemoissa, joille monet modernit koneoppimiskäytännöt perustuvat.
Shatteringin ja kasvufunktioiden tutkimus, ja niiden yhteys VC-ulottuvuuteen, on perustavanlaatuista organisaatioiden kuten Association for the Advancement of Artificial Intelligence ja Institute of Mathematical Statistics työssä, joka edistää tilastollisen oppimisteorian ja sen sovellusten tutkimusta sekä levittämistä.
VC-ulottuvuus ja mallin kapasiteetti: Käytännön merkitys
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, joka tarjoaa tiukan mittauksen joukon funktioiden (hypoteesiluokka) kapasiteetista tai monimutkaisuudesta, jonka koneoppimismalli voi toteuttaa. Käytännön termeissä, VC-ulottuvuus kvantifioi suurimman pistemäärän, joka voidaan shatteroida (eli luokitella oikein kaikilla mahdollisilla tavoilla) mallin avulla. Tämä mittari on kriittinen ymmärtämään kauppasuhteita mallin kyvyssä sovittaa koulutusdataa ja sen kyvyssä yleistää näkymättömiin datan.
Korkeampi VC-ulottuvuus merkitsee ilmaisumallin luokkaa, kykyä esittää monimutkaisempia kuvioita. Esimerkiksi kahden ulottuvuuden lineaarisella luokittajalla on VC-ulottuvuus 3, mikä tarkoittaa, että se voi shatteroida minkä tahansa kolmen pisteen joukon, mutta ei kaikkia neljän pisteen joukkoja. Samaan aikaan monimutkaisemmilla malleilla, kuten monilla parametreilla varustetuilla neuroverkoilla, voi olla huomattavasti korkeampia VC-ulottuvuuksia, mikä heijastaa niiden kykyä sovittaa monimuotoisiin aineistoihin.
VC-ulottuvuuden käytännön merkitys ilmenee selvimmin yliopettamisen ja alimäärityksen kontekstissa. Jos mallin VC-ulottuvuus on paljon suurempi kuin koulutusnäytteiden määrä, malli voi ylinjuuttua – muistaa koulutusdataa sen sijaan, että oppisi yleistettäviä kuvioita. Päinvastoin, jos VC-ulottuvuus on liian matala, malli voi alimäärätä, eikä kykene vangitsemaan datan taustarakennetta. Siksi mallin valinta kohtuullisella VC-ulottuvuudella suhteessa tietojoukon kokoon on tärkeää saavuttaakseen hyvää yleistämissuorituskykyä.
VC-ulottuvuus tukee myös teoreettisia takuita oppimisteoriassa, kuten Oletettavasti Luultavasti Oikein (PAC)-oppimiskehyksessä. Se tarjoaa rajoja sille, kuinka monta koulutusnäytettä tarvitaan, jotta empiirinen riski (virhe koulutusjoukossa) on lähellä todellista riskiä (odotettu virhe uusissa datoissa). Nämä tulokset ohjaavat käytännön asiantuntijoita arvioimaan tarvittavaa näytemäärää luotettavalle oppimiselle, erityisesti korkean riskin sovelluksissa, kuten lääketieteellisessä diagnosoinnissa tai itsenäisissä järjestelmissä.
Käytännössä, vaikka tarkan VC-ulottuvuuden laskeminen monimutkaisille malleille on usein vaikeaa, sen käsitellykäytännöllinen rooli ohjaa algoritmien suunnittelua ja valintaa. Säännöstön hallintatekniikat, mallin valintakriteerit ja ristiinvalidointistrategiat ovat kaikki vaikuttaneet VC-ulottuvuuden periaatteisiin, jotka hallitsevat kapasiteetin kontrollia. Käsite esiteltiin Vladimir Vapnikin ja Alexey Chervonenkisin toimesta, joiden työ loi perustan modernille tilastolliselle oppimisteorialle ja jatkaa vaikuttamistaan koneoppimisessa (Institute of Mathematical Statistics).
Yhteydet yliopettamiseen ja yleistämisen rajoihin
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, joka vaikuttaa suoraan ymmärrykseemme ylinjuuttamisesta ja yleistämisestä koneoppimisessa. VC-ulottuvuus kvantifioi joukon funktioiden (hypoteesiluokka) kapasiteetin tai monimutkaisuuden mittaamalla suurinta pistemäärää, joka voidaan shatteroida—eli luokitella oikein kaikilla mahdollisilla tavoilla—luokan funktioiden avulla. Tämä mittari on keskeinen analysoitaessa, kuinka hyvin malli, joka on koulutettu äärelliselle datalle, tulee toimimaan näkymättömässä datassa, mikä tunnetaan yleistämisen ominaisuutena.
Yliopettaminen tapahtuu, kun malli oppii ei vain taustakuviot, vaan myös koulutusdatassa olevan hälyn, mikä johtaa huonoon suorituskykyyn uusissa, näkymättömissä datoissa. VC-ulottuvuus tarjoaa teoreettisen kehyksen ylinjuuttamisen ymmärtämiseksi ja lieventämiseksi. Jos hypoteesiluokan VC-ulottuvuus on paljon suurempi kuin koulutusnäytteiden lukumäärä, mallilla on riittävästi kapasiteettia sovittaa satunnaista hälyä, mikä lisää riskiä ylinjuuttamisesta. Vastaan, jos VC-ulottuvuus on liian matala, malli voi alimäärätä ja epäonnistua vangitsemaan datan olennaista rakennetta.
Suhde VC-ulottuvuuden ja yleistämisen välillä on formalisoitu yleistämisrajojen avulla. Nämä rajat, kuten ne, jotka on johdettu Vladimir Vapnikin ja Alexey Chervonenkisin perusteellisista töistä, osoittavat, että suurella todennäköisyydellä, empiirisen riskin (virhe koulutusaineistossa) ja todellisen riskin (odotettu virhe uusissa datoissa) välinen ero on pieni, jos koulutusnäytteiden määrä on riittävän suuri suhteessa VC-ulottuvuuteen. Erityisesti yleistämisvirhe pienenee, kun näytteiden määrä kasvaa, edellyttäen että VC-ulottuvuus pysyy kiinteänä. Tämä näkemys tukee periaatetta, että monimutkaisempien mallien (korkeammalla VC-ulottuvuudella) on tarvittava enemmän dataa menestyäkseen yleistämisessä hyvin.
- VC-ulottuvuus on keskeinen teorian homogeenisestä konvergenssista, joka takaa, että empiiriset keskiarvot konvergoivat odotettuihin arvoihin tasaisesti kaikille hypoteesiluokan funktioille. Tämä ominaisuus on oleellinen virheen minimoinnin takaamiseksi koulutusjoukossa, joka johtaa alhaisessa virheeseen näkymättömässä datassa.
- Käsite on myös olennainen rakenteellisen riskin minimoinnin kehittämisessä, strategiassa, joka tasapainottaa mallin monimutkaisuuden ja koulutusvirheen saavuttaakseen optimaalisen yleistämisen, kuten on formalisoitu tukivektorikoneiden ja muiden oppimisalgoritmien teoriassa.
VC-ulottuvuuden merkitys ylinjuuttamiseen ja yleistämiseen liittyen tunnustetaan johtavissa tutkimusinstituutioissa ja se on perustavanlaatuinen tilastollisen oppimisteorian kurssilla, kuten organisaatiot kuten Institute for Advanced Study ja Association for the Advancement of Artificial Intelligence. Nämä organisaatiot edistävät teoreettisten edistysten kehittämistä ja leviämistä koneoppimisessa.
VC-ulottuvuus todellisten koneoppimisalgoritmien yhteydessä
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, joka tarjoaa tiukan mittauksen joukon funktioiden (hypoteesiluokka) kapasiteetista tai monimutkaisuudesta, jonka koneoppimisalgoritmi voi toteuttaa. Todellisessa koneoppimisessa VC-ulottuvuus on kriittinen ymmärtämään algoritmien yleistämiskykyä—kuinka hyvin malli, joka on koulutettu äärelliseltä näytteeltä, tulee toimimaan näkymättömien datoiden kanssa.
Käytännön termeissä VC-ulottuvuus auttaa kvantifioimaan kauppasuhteen mallin monimutkaisuuden ja ylinjuuttamisen riskin välillä. Esimerkiksi kahden ulottuvuuden lineaarisella luokittajalla (kuten perceptronilla) on VC-ulottuvuus 3, mikä tarkoittaa, että se voi shatteroida minkä tahansa kolmen pisteen joukon, mutta ei kaikkia neljän pisteen joukkoja. Monimutkaisemmilla malleilla, kuten neuroverkoilla, voi olla paljon suurempia VC-ulottuvuuksia, mikä heijastaa niiden kykyä sovittaa monimutkaisempia kuvioita datassa. Kuitenkin, korkeemmalla VC-ulottuvuudella on myös suurempi riski ylinjuuttamisesta, jolloin malli vangitsee hälyn enemminkin kuin taustarakennetta.
VC-ulottuvuus on erityisen merkityksellinen Oletettavasti Luultavasti Oikein (PAC) -oppimiskehyksen yhteydessä, joka tarjoaa teoreettisia takuita sille, kuinka monta koulutusnäytettä tarvitaan saavuttamaan haluttu tarkkuus- ja luottamustaso. Teorian mukaan näytemäärä—oppimiselle tarvittavat esimerkit—kasvaa hypoteesiluokan VC-ulottuvuuden myötä. Tämä suhde ohjaa käytännön asiantuntijoita valitsemaan sopivia malliluokkia ja säännöstön hallintastrategioita, jotta ilmaisukykyä ja yleistämistä voitaisiin tasapainottaa.
Todellisissa sovelluksissa VC-ulottuvuus ohjaa algoritmien suunnittelua ja arviointia, kuten tukivektorikoneita (SVM), päätöspuita ja neuroverkkoja. Esimerkiksi, SVM:t ovat tiiviisti kytkettyjä VC-teoriaan, koska niiden marginaalista maksimointiperiaate voidaan tulkita keinoksi kontrolloida luokittelijan tehokasta VC-ulottuvuutta, parantaen näin yleistämissuorituskykyä. Vastaavasti päätöspuiden leikkausmenetelmät voidaan nähdä VC-ulottuvuuden vähentämiseen ja ylinjuuttamisen lieventämiseen tähtäävinä keinoina.
Vaikka monimutkaisten mallien, kuten syvien neuroverkkojen, tarkka VC-ulottuvuuden laskeminen on usein vaikeaa, käsite vaikuttaa edelleen tutkimuksen ja käytännön ohjaamiseen. Se tukee säännöstön hallintamenetelmien, mallin valintakriteerien ja teoreettisten rajoitusten kehittämistä oppimissuorituskyvyn osalta. VC-ulottuvuuden jatkuva merkitys heijastuu sen perustavanlaatuiseen rooliin organisaatioiden, kuten Association for the Advancement of Artificial Intelligence ja Association for Computing Machinery, työssä, jotka edistävät tutkimusta koneoppimisteoriassa ja sen käytännön sovelluksissa.
VC-ulottuvuuden rajoitukset ja kritiikki
Vapnik–Chervonenkis (VC) -ulottuvuus on perustavanlaatuinen käsite tilastollisessa oppimisteoriassa, joka tarjoaa mittauksen funktiojoukon (hypoteesiluokka) kapasiteetista tai monimutkaisuudesta sen kyvyssä shatteroida datapisteet. Huolimatta teoreettisesta merkityksestään, VC-ulottuvuudella on useita huomattavia rajoituksia ja se on saanut osakseen erilaista kritiikkiä koneoppimis- ja tilastoyhteisöissä.
Yksi VC-ulottuvuuden päärajoituksista on sen keskittyminen pahimman mahdollisen skenaarion analysoimiseen. VC-ulottuvuus kvantifioi suurimman pistejoukon, joka voidaan shatteroida hypoteesiluokan avulla, mutta tämä ei aina heijasta tyypillistä tai keskiarvoa suoriutumista oppimisalgoritmeissa käytännön ympäristöissä. Tämän seurauksena VC-ulottuvuus voi yliarvioida todellista monimutkaisuutta, joka vaaditaan menestyvään yleistämiseen todellisissa tiedoissa, joissa jakaumat ovat usein kaukana vastustavasta tai pahimmasta mahdollisesta tilanteesta. Tämä epäyhteensopivuus voi johtaa kohtuuttoman pessimistisiin rajoihin näytemonimutkaisuudelle ja yleistämisvirheelle.
Toinen kritiikki koskee VC-ulottuvuuden soveltuvuutta nykyaikaisiin koneoppimisalgoritmeihin, erityisesti syviin neuroverkkoihin. Vaikka VC-ulottuvuus on hyvin määritelty yksinkertaisille hypoteesiluokille, kuten lineaarisille luokittajille tai päätöspuille, sen laskeminen tai jopa merkityksellisesti tulkitseminen erittäin parametrisoituille malleille on vaikeaa. Monissa tapauksissa syvillä verkoilla voi olla äärettömän korkeita tai jopa äärettömiä VC-ulottuvuuksia ja silti yleistää hyvin käytännössä. Tämä ilmiö, jota joskus kutsutaan ”yleistämisen paradokseiksi”, viittaa siihen, että VC-ulottuvuus ei täysin kata niitä tekijöitä, jotka hallitsevat yleistämistä nykyaikaisissa koneoppimissysteemissä.
Lisäksi VC-ulottuvuudella on luontaisesti yhdistettävä mitta, joka jättää huomiotta datanjakautuman geometrisen ja rakenteellisen. Se ei ota huomioon marginaalitiedon, säännöstön tai muiden algoritmisen lähestymistavan tekijöiden vaikutusta yleistämiseen. Vaihtoehtoisia monimutkaisuusmittareita, kuten Rademacher-monimutkaisuus tai peittävä luku, on ehdotettu, jotta nämä puutteet voidaan osittain korjata sisällyttämällä dataan perustuvia tai geometrian asiayhteyksiä.
Lopuksi VC-ulottuvuus olettaa, että datapisteet ovat riippumattomia ja identtisesti jaettuja (i.i.d.), mikä olettamus ei välttämättä päde monissa käytännön sovelluksissa, kuten aikasarjatestaamisessa tai strukturoitujen ennustusten tehtävissä. Tämä rajoittaa entisestään suoraa soveltuvuutta VC-pohjaiseen teoriaan tietyissä alueissa.
Huolimatta näistä rajoituksista VC-ulottuvuus pysyy oppimisteorian kulmakivenä, joka tarjoaa arvokkaita näkemyksiä oppimisen perustavissa rajoissa. Jatkuva tutkimus organisaatioissa, kuten Association for the Advancement of Artificial Intelligence ja Institute of Mathematical Statistics, jatkaa VC-kehyksen laajennusten ja vaihtoehtojen tutkimista, pyrkien paremmin sovittamaan teoreettiset taatut havainnot nykyaikaiseen koneoppimiseen.
Tulevaisuuden suuntaukset ja avoimet ongelmat VC-teoriassa
Vapnik–Chervonenkis (VC) -ulottuvuus pysyy perustavanlaatuisena tilastollisessa oppimisteoriassa, tarjoten tiukan mittauksen hypoteesiluokkien kapasiteetista ja niiden kyvystä yleistää äärellisistä näytteistä. Huolimatta perustavanlaatuisesta roolistaan, useita tulevia suuntauksia ja avoimia ongelmia jatkaa VC-teorian tutkimusta, heijastaen sekä teoreettisia haasteita että käytännön tarpeita nykyaikaisessa koneoppimisessa.
Yksi merkittävä suunta on VC-teorian laajentaminen monimutkaisempiin ja rakenteellisiin tietodomeeneihin. Perinteinen VC-ulottuvuusanalyysi soveltuu hyvin binääriseen luokitteluun ja yksinkertaisiin hypoteesitiloihin, mutta nykyaikaiset sovellukset käsittävät usein moniluokkaisia, rakenteellisia tulosteita tai dataa, jossa on monimutkaisia riippuvuuksia. Yleistetyn VC-ulottuvuuden kehittäminen, joka voi vangita syvien neuroverkkojen, toistuvien arkkitehtuurien ja muiden edistyneiden mallien monimutkaisuden, pysyy avoimena haasteena. Tämä sisältää mallien todellisen kapasiteetin ymmärtämisen ja sen miten se liittyy niiden empiiriseen suorituskykyyn ja yleistämiskykyyn.
Toinen aktiivinen tutkimusalue on VC-ulottuvuuden laskentatekninen ulottuvuus. Vaikka VC-ulottuvuus tarjoaa teoreettisia takuita, sen laskeminen tai edes arvioiminen satunnaisten hypoteesiluokkien osalta on usein mahdotonta. Tehokkaat algoritmit VC-ulottuvuuden arvioimiseksi, erityisesti suurilla tai korkean ulottuvuuden malleilla, ovat erittäin kysyttyjä. Tämä vaikuttaa mallin valintaan, säännöstön hallintaan ja oppimisalgoritmien suunnitteluun, jotka voivat mukautuvasti kontrolloida mallin monimutkaisuutta.
VC-ulottuvuuden ja muiden monimutkaisuusmittareiden, kuten Rademacher-monimutkaisuuden, peittävän numeron ja algoritmisen vakavuuden, välinen suhde tarjoaa myös hedelmällistä tutkimusmaata. Kun koneoppimismallit muuttuvat yhä monimutkaisemmiksi, ymmärtäminen siitä, miten nämä erilaiset mittarit vuorovaikuttavat ja mitkä ennustavat parhaiten yleistämistä käytännössä, on keskeinen avoin ongelma. Tämä on erityisen merkityksellistä yliparannetuissa malleissa, joissa klassinen VC-teoria ei välttämättä täysin selitä havaittuja yleistämisilmiöitä.
Lisäksi tietosuoja- ja oikeudenmukaisuusongelmat tuovat uusia ulottuvuuksia VC-teoriaan. Tutkijat tutkivat, miten säännökset, kuten eroa ja oikeudenmukaisuusvaatimuksia, vaikuttavat VC-ulottuvuuteen ja siten hypoteesiluokkien oppimiskykyyn näiden rajoitusten alla. Tämä VC-teorian ja eettisten sekä oikeudellisten näkökohtien risteys kasvaa todennäköisesti merkitykseltään, kun koneoppimisjärjestelmiä yhä useammin otetaan käyttöön herkissä ympäristöissä.
Lopuksi kvanttitietojenkäsittelyn jatkuva kehittäminen ja sen mahdolliset sovellukset koneoppimisessa herättävät kysymyksiä VC-ulottuvuudesta kvantti-hypoteesitiloissa. Ymmärtäminen siitä, kuinka kvanttiresurssit vaikuttavat oppimisalgoritmien kapasiteettiin ja yleistämiseen, on nouseva teoreettinen tutkimusalue.
Kun ala kehittyy, organisaatiot, kuten Association for the Advancement of Artificial Intelligence ja Institute of Mathematical Statistics, tukevat jatkossakin VC-teorian kehittämistä ja edistämistä, varmistaen, että perustavanlaatuiset kysymykset pysyvät koneoppimisen tutkimuksen keskiössä.
Lähteet ja viitteet