Démystifier la dimension de Vapnik–Chervonenkis : La clé pour comprendre la complexité des modèles et la généralisation en apprentissage automatique. Découvrez comment la dimension VC façonne les limites de ce que les algorithmes peuvent apprendre.
- Introduction à la dimension de Vapnik–Chervonenkis
- Origines historiques et fondements théoriques
- Définition formelle et cadre mathématique
- Dimension VC dans la classification binaire
- Shattering, fonctions de croissance et leur signification
- Dimension VC et capacité du modèle : Implications pratiques
- Connexions à l’overfitting et aux bornes de généralisation
- Dimension VC dans les algorithmes d’apprentissage automatique du monde réel
- Limitations et critiques de la dimension VC
- Directions futures et problèmes ouverts en théorie VC
- Sources & Références
Introduction à la dimension de Vapnik–Chervonenkis
La dimension de Vapnik–Chervonenkis (dimension VC) est un concept fondamental en théorie de l’apprentissage statistique, introduit par Vladimir Vapnik et Alexey Chervonenkis au début des années 1970. Elle fournit un cadre mathématique rigoureux pour quantifier la capacité ou la complexité d’un ensemble de fonctions (classe d’hypothèses) en termes de sa capacité à classifier des points de données. La dimension VC est définie comme le plus grand nombre de points pouvant être « shatter » (c’est-à-dire correctement classifiés de toutes les manières possibles) par la classe d’hypothèses. Ce concept est central pour comprendre la capacité de généralisation des algorithmes d’apprentissage, car il relie l’expressivité d’un modèle à son risque d’overfitting.
De manière plus formelle, si une classe d’hypothèses peut shatter un ensemble de n points, mais ne peut pas shatter un ensemble de n+1 points, alors sa dimension VC est n. Par exemple, la classe des classificateurs linéaires dans un espace bidimensionnel a une dimension VC de 3, ce qui signifie qu’elle peut shatter n’importe quel ensemble de trois points, mais pas tous les ensembles de quatre points. La dimension VC sert ainsi de mesure de la richesse d’une classe d’hypothèses, indépendante de la distribution spécifique des données.
L’importance de la dimension VC réside dans son rôle en fournissant des garanties théoriques pour les algorithmes d’apprentissage automatique. C’est un composant clé dans la dérivation des bornes sur l’erreur de généralisation, qui est la différence entre l’erreur sur les données d’entraînement et l’erreur attendue sur des données non vues. L’inégalité VC célèbre, par exemple, relie la dimension VC à la probabilité que le risque empirique (erreur d’entraînement) s’écarte du risque réel (erreur de généralisation). Cette relation sous-tend le principe de minimisation du risque structurel, un pilier de la théorie de l’apprentissage statistique moderne, qui cherche à équilibrer la complexité du modèle et l’erreur d’entraînement pour obtenir une généralisation optimale.
Le concept de dimension VC a été largement adopté dans l’analyse de divers algorithmes d’apprentissage, y compris les machines à vecteurs de support, les réseaux de neurones et les arbres de décision. Il est également fondamental dans le développement du cadre d’apprentissage Probablement Approximativement Correct (PAC), qui formalise les conditions selon lesquelles un algorithme d’apprentissage peut être attendu pour bien performer. Les fondements théoriques fournis par la dimension VC ont été instrumentaux dans l’avancement du domaine de l’apprentissage automatique et sont reconnus par des institutions de recherche de premier plan telles que l’Institut d’Études Avancées et l’Association pour l’Avancement de l’Intelligence Artificielle.
Origines historiques et fondements théoriques
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, introduit au début des années 1970 par Vladimir Vapnik et Alexey Chervonenkis. Leur travail pionnier a émergé de l’Institut des Sciences de Contrôle de l’Académie des Sciences de Russie, où ils ont cherché à formaliser les principes sous-jacents à la reconnaissance de motifs et à l’apprentissage automatique. La dimension VC fournit un cadre mathématique rigoureux pour quantifier la capacité d’un ensemble de fonctions (classe d’hypothèses) à adapter des données, ce qui est crucial pour comprendre la capacité de généralisation des algorithmes d’apprentissage.
Au cœur de la dimension VC se mesure le plus grand nombre de points pouvant être shatter par une classe d’hypothèses. Si une classe de fonctions peut shatter un ensemble de taille d mais pas d+1, sa dimension VC est d. Ce concept permet aux chercheurs d’analyser le compromis entre la complexité du modèle et le risque d’overfitting, une préoccupation centrale en apprentissage automatique. L’introduction de la dimension VC a marqué un avancement significatif par rapport aux approches antérieures, moins formelles, de la théorie de l’apprentissage, fournissant un pont entre la performance empirique et les garanties théoriques.
Les fondements théoriques de la dimension VC sont étroitement liés au développement du cadre d’apprentissage Probablement Approximativement Correct (PAC), qui formalise les conditions selon lesquelles un algorithme d’apprentissage peut être attendu pour bien performer sur des données non vues. La dimension VC sert de paramètre clé dans les théorèmes qui bornent l’erreur de généralisation des classificateurs, établissant qu’une dimension VC finie est nécessaire pour la capacité d’apprentissage dans le sens PAC. Cette perspective a eu un impact profond sur la conception et l’analyse des algorithmes dans des domaines allant de la vision par ordinateur au traitement du langage naturel.
Le travail de Vapnik et Chervonenkis a jeté les bases du développement des machines à vecteurs de support et d’autres méthodes basées sur les noyaux, qui reposent sur les principes de contrôle de la capacité et de minimisation du risque structurel. Leurs contributions ont été reconnues par des organisations scientifiques de premier plan, et la dimension VC demeure un sujet central dans le programme des cours avancés d’apprentissage automatique et de statistiques à travers le monde. La Société Mathématique Américaine et l’Association pour l’Avancement de l’Intelligence Artificielle figurent parmi les organismes qui ont souligné l’importance de ces avancées théoriques dans leurs publications et conférences.
Définition formelle et cadre mathématique
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, fournissant une mesure rigoureuse de la capacité ou de la complexité d’un ensemble de fonctions (classe d’hypothèses) en termes de sa capacité à classifier des points de données. Formèlement, la dimension VC est définie pour une classe de fonctions indicatrices (ou ensembles) comme le plus grand nombre de points pouvant être shatter par la classe. « Shatter » un ensemble de points signifie que, pour chaque étiquetage possible de ces points, il existe une fonction dans la classe qui assigne correctement ces étiquettes.
Soit H une classe d’hypothèses de fonctions de valeur binaire mappant d’un espace d’entrée X vers {0,1}. Un ensemble de points S = {x₁, x₂, …, xₙ} est dit shatter par H si, pour chaque sous-ensemble possible A de S, il existe une fonction h ∈ H telle que h(x) = 1 si et seulement si x ∈ A. La dimension VC de H, notée VC(H), est la cardinalité maximale n telle qu’il existe un ensemble de n points dans X shatter par H. Si des ensembles de taille finie arbitrairement grande peuvent être shatter, la dimension VC est infinie.
Mathématiquement, la dimension VC fournit un lien entre l’expressivité d’une classe d’hypothèses et sa capacité de généralisation. Une dimension VC plus élevée indique une classe plus expressive, capable d’adapter des motifs plus complexes, mais également à un risque plus élevé d’overfitting. À l’inverse, une dimension VC plus basse suggère une expressivité limitée et potentiellement une meilleure généralisation, mais peut-être au prix d’un sous-ajustement. La dimension VC est centrale dans la dérivation des bornes de généralisation, telles que celles formalisées dans les théorèmes fondamentaux de la théorie de l’apprentissage statistique, qui relient la dimension VC à la complexité d’échantillon requise pour apprendre avec une précision et une confiance données.
Le concept a été introduit par Vladimir Vapnik et Alexey Chervonenkis dans les années 1970, et il sous-tend l’analyse théorique des algorithmes d’apprentissage, y compris les machines à vecteurs de support et les cadres de minimisation du risque empirique. La dimension VC est largement reconnue et utilisée dans le domaine de l’apprentissage automatique et est discutée en détail par des organisations telles que l’Institut de Statistiques Mathématiques et l’Association pour l’Avancement de l’Intelligence Artificielle, qui sont toutes deux des autorités de premier plan dans la recherche en statistiques et en intelligence artificielle, respectivement.
Dimension VC dans la classification binaire
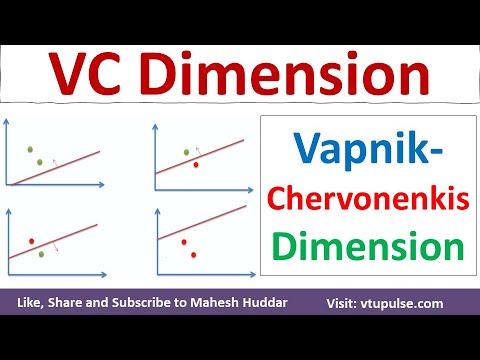
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, particulièrement pertinent pour l’analyse des modèles de classification binaire. Introduite par Vladimir Vapnik et Alexey Chervonenkis au début des années 1970, la dimension VC quantifie la capacité ou la complexité d’un ensemble de fonctions (classe d’hypothèses) en mesurant sa capacité à shatter des ensembles finis de points de données. Dans le contexte de la classification binaire, « shattering » fait référence à la capacité d’un classificateur à étiqueter correctement toutes les affectations possibles d’étiquettes binaires (0 ou 1) à un ensemble donné de points.
Formellement, la dimension VC d’une classe d’hypothèses est le plus grand nombre de points pouvant être shatter par cette classe. Par exemple, considérons la classe des classificateurs linéaires (perceptrons) dans un espace bidimensionnel. Cette classe peut shatter n’importe quel ensemble de trois points en position générale, mais pas tous les ensembles de quatre points. Par conséquent, la dimension VC des classificateurs linéaires dans deux dimensions est trois. La dimension VC fournit une mesure de l’expressivité d’un modèle : une dimension VC plus élevée indique un modèle plus flexible capable d’adapter des motifs plus complexes, mais augmente également le risque d’overfitting.
Dans la classification binaire, la dimension VC joue un rôle crucial dans la compréhension du compromis entre la complexité du modèle et la généralisation. Selon la théorie, si la dimension VC est trop élevée par rapport au nombre d’échantillons d’entraînement, le modèle peut bien s’ajuster aux données d’entraînement mais échouer à généraliser à des données non vues. À l’inverse, un modèle avec une dimension VC faible peut sous-ajuster, ne parvenant pas à capturer des motifs importants dans les données. Ainsi, la dimension VC fournit des garanties théoriques sur l’erreur de généralisation, comme formalisé dans l’inégalité VC et les bornes connexes.
Le concept de dimension VC est central au développement des algorithmes d’apprentissage et à l’analyse de leur performance. Il sous-tend le cadre d’apprentissage Probablement Approximativement Correct (PAC), qui caractérise les conditions dans lesquelles un algorithme d’apprentissage peut atteindre une faible erreur de généralisation avec une forte probabilité. La dimension VC est également utilisée dans la conception et l’analyse des machines à vecteurs de support (SVM), une classe de classificateurs binaires largement utilisée, ainsi que dans l’étude des réseaux de neurones et d’autres modèles d’apprentissage automatique.
L’importance de la dimension VC dans la classification binaire est reconnue par des institutions de recherche et des organisations de premier plan dans le domaine de l’intelligence artificielle et de l’apprentissage automatique, telles que l’Association pour l’Avancement de l’Intelligence Artificielle et l’Association for Computing Machinery. Ces organisations soutiennent la recherche et la diffusion de concepts fondamentaux tels que la dimension VC, qui continuent de façonner les fondements théoriques et les applications pratiques de l’apprentissage automatique.
Shattering, fonctions de croissance et leur signification
Les concepts de shattering et de fonctions de croissance sont centraux pour comprendre la dimension de Vapnik–Chervonenkis (VC), une mesure fondamentale en théorie de l’apprentissage statistique. La dimension VC, introduite par Vladimir Vapnik et Alexey Chervonenkis, quantifie la capacité d’un ensemble de fonctions (classe d’hypothèses) à adapter des données, et est cruciale pour analyser la capacité de généralisation des algorithmes d’apprentissage.
Le shattering fait référence à la capacité d’une classe d’hypothèses à classer parfaitement tous les étiquetages possibles d’un ensemble fini de points. Formellement, un ensemble de points est dit shatter par une classe d’hypothèses si, pour chaque affectation possible d’étiquettes binaires aux points, il existe une fonction dans la classe qui sépare correctement les points selon ces étiquettes. Par exemple, dans le cas des classificateurs linéaires en deux dimensions, tout ensemble de trois points non colinéaires peut être shatter, mais pas tous les ensembles de quatre points.
La fonction de croissance, également connue sous le nom de coefficient de shattering, mesure le nombre maximum d’étiquetages distincts (dichotomies) qu’une classe d’hypothèses peut réaliser sur n’importe quel ensemble de n points. Si la classe d’hypothèses peut shatter chaque ensemble de n points, la fonction de croissance est égale à 2n. Cependant, à mesure que n augmente, la plupart des classes d’hypothèses atteignent un point où elles ne peuvent plus shatter tous les étiquetages possibles, et la fonction de croissance augmente plus lentement. La dimension VC est définie comme le plus grand entier d tel que la fonction de croissance égale 2d ; en d’autres termes, c’est la taille du plus grand ensemble qui peut être shatter par la classe d’hypothèses.
Ces concepts sont significatifs car ils fournissent un moyen rigoureux d’analyser la complexité et le pouvoir expressif des modèles d’apprentissage. Une dimension VC plus élevée indique un modèle plus expressif, capable d’adapter des motifs plus complexes, mais également à un risque plus élevé d’overfitting. À l’inverse, une faible dimension VC suggère une capacité limitée, ce qui peut entraîner un sous-ajustement. La dimension VC est directement liée aux bornes de généralisation : elle aide à déterminer combien de données d’entraînement sont nécessaires pour garantir que la performance du modèle sur des données non vues sera proche de sa performance sur l’ensemble d’entraînement. Cette relation est formalisée dans des théorèmes tels que le théorème fondamental de l’apprentissage statistique, qui sous-tend une grande partie de la théorie moderne de l’apprentissage automatique.
L’étude du shattering et des fonctions de croissance, ainsi que leur connexion à la dimension VC, est fondamentale dans le travail d’organisations telles que l’Association pour l’Avancement de l’Intelligence Artificielle et l’Institut de Statistiques Mathématiques, qui promeuvent la recherche et la diffusion des avancées de la théorie de l’apprentissage statistique et de ses applications.
Dimension VC et capacité du modèle : Implications pratiques
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, fournissant une mesure rigoureuse de la capacité ou de la complexité d’un ensemble de fonctions (classe d’hypothèses) qu’un modèle d’apprentissage automatique peut implémenter. En termes pratiques, la dimension VC quantifie le plus grand nombre de points pouvant être shatter (c’est-à-dire correctement classifiés de toutes les manières possibles) par le modèle. Cette mesure est cruciale pour comprendre le compromis entre la capacité d’un modèle à s’ajuster aux données d’entraînement et sa capacité à généraliser à des données non vues.
Une dimension VC plus élevée indique une classe de modèles plus expressive, capable de représenter des motifs plus complexes. Par exemple, un classificateur linéaire dans un espace bidimensionnel a une dimension VC de 3, ce qui signifie qu’il peut shatter n’importe quel ensemble de trois points, mais pas tous les ensembles de quatre. En revanche, des modèles plus complexes, tels que les réseaux de neurones avec de nombreux paramètres, peuvent avoir des dimensions VC beaucoup plus élevées, reflétant leur plus grande capacité à s’ajuster à des ensembles de données divers.
Les implications pratiques de la dimension VC sont les plus évidentes dans le contexte de l’overfitting et du sous-ajustement. Si la dimension VC d’un modèle est beaucoup plus grande que le nombre d’échantillons d’entraînement, le modèle peut overfitter – mémorisant les données d’entraînement plutôt que d’apprendre des motifs généralisables. À l’inverse, si la dimension VC est trop basse, le modèle peut sous-ajuster, ne parvenant pas à capturer la structure sous-jacente des données. Ainsi, le choix d’un modèle avec une dimension VC appropriée par rapport à la taille de l’ensemble de données est essentiel pour obtenir une bonne performance de généralisation.
La dimension VC sous-tend également des garanties théoriques en théorie de l’apprentissage, telles que le cadre d’apprentissage Probablement Approximativement Correct (PAC). Elle fournit des bornes sur le nombre d’échantillons d’entraînement nécessaires pour garantir que le risque empirique (erreur sur l’ensemble d’entraînement) est proche du risque réel (erreur attendue sur de nouvelles données). Ces résultats guident les praticiens dans l’estimation de la complexité d’échantillon nécessaire pour un apprentissage fiable, en particulier dans des applications à enjeux élevés telles que le diagnostic médical ou les systèmes autonomes.
Dans la pratique, bien que la dimension VC exacte soit souvent difficile à calculer pour des modèles complexes, son rôle conceptuel informe la conception et la sélection des algorithmes. Les techniques de régularisation, les critères de sélection de modèles et les stratégies de validation croisée sont toutes influencées par les principes sous-jacents du contrôle de capacité articulés par la dimension VC. Ce concept a été introduit par Vladimir Vapnik et Alexey Chervonenkis, dont le travail a jeté les bases de la théorie de l’apprentissage statistique moderne et continue d’influencer les recherches et applications en apprentissage automatique (Institut de Statistiques Mathématiques).
Connexions à l’overfitting et aux bornes de généralisation
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, influençant directement notre compréhension de l’overfitting et de la généralisation dans les modèles d’apprentissage automatique. La dimension VC quantifie la capacité ou la complexité d’un ensemble de fonctions (classe d’hypothèses) en mesurant le plus grand ensemble de points pouvant être shatter – c’est-à-dire correctement classifié de toutes les manières possibles – par les fonctions de la classe. Cette mesure est cruciale pour analyser à quel point un modèle formé sur un ensemble de données fini performera sur des données non vues, une propriété connue sous le nom de généralisation.
L’overfitting se produit lorsqu’un modèle apprend non seulement les motifs sous-jacents mais aussi le bruit dans les données d’entraînement, ce qui entraîne de mauvaises performances sur de nouvelles, données non vues. La dimension VC fournit un cadre théorique pour comprendre et atténuer l’overfitting. Si la dimension VC d’une classe d’hypothèses est beaucoup plus grande que le nombre d’échantillons d’entraînement, le modèle a suffisamment de capacité pour s’ajuster au bruit aléatoire, augmentant ainsi le risque d’overfitting. À l’inverse, si la dimension VC est trop basse, le modèle peut sous-ajuster, ne parvenant pas à capturer la structure essentielle des données.
La relation entre la dimension VC et la généralisation est formalisée à travers des bornes de généralisation. Ces bornes, telles que celles dérivées du travail fondamental de Vladimir Vapnik et Alexey Chervonenkis, indiquent qu’avec une grande probabilité, la différence entre le risque empirique (erreur sur l’ensemble d’entraînement) et le risque vrai (erreur attendue sur de nouvelles données) est faible si le nombre d’échantillons d’entraînement est suffisamment grand par rapport à la dimension VC. Plus précisément, l’erreur de généralisation diminue à mesure que le nombre d’échantillons augmente, à condition que la dimension VC reste fixe. Cette perspective sous-tend le principe selon lequel des modèles plus complexes (avec une dimension VC plus élevée) nécessitent plus de données pour bien généraliser.
- La dimension VC est centrale à la théorie de la convergence uniforme, qui garantit que les moyennes empiriques convergent vers des valeurs attendues uniformément pour toutes les fonctions de la classe d’hypothèses. Cette propriété est essentielle pour garantir que la minimisation de l’erreur sur l’ensemble d’entraînement conduit à une faible erreur sur des données non vues.
- Le concept est également intégral au développement de la minimisation du risque structurel, une stratégie qui équilibre la complexité du modèle et l’erreur d’entraînement pour atteindre une généralisation optimale, comme formalisé dans la théorie des machines à vecteurs de support et d’autres algorithmes d’apprentissage.
L’importance de la dimension VC dans la compréhension de l’overfitting et de la généralisation est reconnue par des institutions de recherche de premier plan et est fondamentale dans le programme de la théorie de l’apprentissage statistique, comme le souligne des organisations telles que l’Institut d’Études Avancées et l’Association pour l’Avancement de l’Intelligence Artificielle. Ces organisations contribuent au développement continu et à la diffusion des avancées théoriques dans l’apprentissage automatique.
Dimension VC dans les algorithmes d’apprentissage automatique du monde réel
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, fournissant une mesure rigoureuse de la capacité ou de la complexité d’un ensemble de fonctions (classe d’hypothèses) qu’un algorithme d’apprentissage automatique peut implémenter. Dans l’apprentissage automatique du monde réel, la dimension VC joue un rôle crucial pour comprendre la capacité de généralisation des algorithmes – à quel point un modèle formé sur un échantillon fini est censé performer sur des données non vues.
Pratiquement, la dimension VC aide à quantifier le compromis entre la complexité du modèle et le risque d’overfitting. Par exemple, un classificateur linéaire dans un espace bidimensionnel (tel qu’un perceptron) a une dimension VC de 3, ce qui signifie qu’il peut shatter n’importe quel ensemble de trois points mais pas tous les ensembles de quatre. Les modèles plus complexes, tels que les réseaux de neurones, peuvent avoir des dimensions VC beaucoup plus élevées, reflétant leur capacité à s’ajuster à des motifs plus complexes dans les données. Cependant, une dimension VC plus élevée augmente également le risque d’overfitting, où le modèle capture le bruit plutôt que la structure sous-jacente.
La dimension VC est particulièrement pertinente dans le contexte du cadre d’apprentissage Probablement Approximativement Correct (PAC), qui fournit des garanties théoriques sur le nombre d’échantillons d’entraînement requis pour atteindre un niveau souhaité de précision et de confiance. Selon la théorie, la complexité d’échantillon – le nombre d’exemples nécessaires pour l’apprentissage – augmente avec la dimension VC de la classe d’hypothèses. Cette relation guide les praticiens dans la sélection de classes de modèles appropriées et de stratégies de régularisation pour équilibrer expressivité et généralisation.
Dans les applications réelles, la dimension VC informe la conception et l’évaluation d’algorithmes tels que les machines à vecteurs de support (SVM), les arbres de décision et les réseaux de neurones. Par exemple, les SVM sont étroitement liés à la théorie VC, car leur principe de maximisation de marge peut être interprété comme un moyen de contrôler la dimension VC effective du classificateur, améliorant ainsi la performance de généralisation. De même, les techniques d’élagage dans les arbres de décision peuvent être considérées comme des méthodes pour réduire la dimension VC et atténuer l’overfitting.
Bien que la dimension VC exacte de modèles complexes comme les réseaux de neurones profonds soit souvent difficile à calculer, le concept reste influent pour guider la recherche et la pratique. Il sous-tend le développement de méthodes de régularisation, de critères de sélection de modèles et de bornes théoriques sur la performance d’apprentissage. La pertinence durable de la dimension VC se reflète dans son rôle fondamental dans le travail d’organisations telles que l’Association pour l’Avancement de l’Intelligence Artificielle et l’Association for Computing Machinery, qui promeuvent la recherche dans la théorie de l’apprentissage automatique et ses implications pratiques.
Limitations et critiques de la dimension VC
La dimension de Vapnik–Chervonenkis (VC) est un concept fondamental en théorie de l’apprentissage statistique, fournissant une mesure de la capacité ou de la complexité d’un ensemble de fonctions (classe d’hypothèses) en termes de sa capacité à shatter des points de données. Malgré son importance théorique, la dimension VC présente plusieurs limitations notables et a été soumise à diverses critiques au sein des communautés d’apprentissage automatique et statistique.
Une limitation principale de la dimension VC est son accent mis sur les scénarios extrêmes. La dimension VC quantifie le plus grand ensemble de points pouvant être shatter par une classe d’hypothèses, mais cela ne reflète pas toujours la performance typique ou moyenne des algorithmes d’apprentissage dans des contextes pratiques. En conséquence, la dimension VC peut surestimer la véritable complexité requise pour une généralisation réussie dans des données du monde réel, où les distributions sont souvent loin d’être adversariales ou dans le pire des cas. Cela peut entraîner des bornes excessivement pessimistes sur la complexité d’échantillon et l’erreur de généralisation.
Une autre critique concerne l’applicabilité de la dimension VC aux modèles d’apprentissage automatique modernes, en particulier les réseaux de neurones profonds. Bien que la dimension VC soit bien définie pour des classes d’hypothèses simples telles que les classificateurs linéaires ou les arbres de décision, elle devient difficile à calculer ou même à interpréter de manière significative pour des modèles hautement paramétrés. Dans de nombreux cas, les réseaux profonds peuvent avoir des dimensions VC extrêmement élevées voire infinies, tout en se généralisant bien dans la pratique. Ce phénomène, parfois appelé le « paradoxe de généralisation », suggère que la dimension VC ne capture pas pleinement les facteurs qui régissent la généralisation dans les systèmes d’apprentissage automatique contemporains.
De plus, la dimension VC est de manière intrinsèque une mesure combinatoire, ignorant la géométrie et la structure de la distribution des données. Elle ne tient pas compte des propriétés basées sur les marges, de la régularisation ou d’autres techniques algorithmiques qui peuvent affekt de manière significative la généralisation. Des mesures de complexité alternatives, telles que la complexité de Rademacher ou les nombres de couverture, ont été proposées pour traiter certaines de ces lacunes en incorporant des aspects dépendant des données ou géométriques.
Enfin, la dimension VC suppose que les points de données sont indépendants et identiquement distribués (i.i.d.), une hypothèse qui peut ne pas tenir dans de nombreuses applications réelles, telles que les analyses de séries temporelles ou les tâches de prédiction structurées. Cela limite encore l’applicabilité directe de la théorie basée sur la VC dans certains domaines.
Malgré ces limitations, la dimension VC demeure un pilier de la théorie de l’apprentissage, fournissant des éclairages précieux sur les limites fondamentales de l’apprentissage. La recherche continue d’organisations telles que l’Association pour l’Avancement de l’Intelligence Artificielle et l’Institut de Statistiques Mathématiques continue d’explorer les extensions et alternatives au cadre VC, visant à mieux aligner les garanties théoriques avec les observations empiriques dans l’apprentissage automatique moderne.
Directions futures et problèmes ouverts en théorie VC
La dimension de Vapnik–Chervonenkis (VC) reste un pilier de la théorie de l’apprentissage statistique, fournissant une mesure rigoureuse de la capacité des classes d’hypothèses et de leur capacité à généraliser à partir d’échantillons finis. Malgré son rôle fondamental, plusieurs directions futures et problèmes ouverts continuent de solliciter la recherche en théorie VC, reflétant à la fois des défis théoriques et des demandes pratiques dans l’apprentissage automatique moderne.
Une direction importante est l’extension de la théorie VC à des domaines de données plus complexes et structurés. L’analyse traditionnelle de la dimension VC est bien adaptée à la classification binaire et aux espaces d’hypothèses simples, mais les applications modernes impliquent souvent des sorties multi-classes, des données structurées ou des données avec des dépendances complexes. Développer des notions généralisées de dimension VC qui peuvent capturer la complexité des réseaux de neurones profonds, des architectures récurrentes et d’autres modèles avancés demeure un défi ouvert. Cela inclut la compréhension de la capacité effective de ces modèles et comment elle se relie à leur performance empirique et leur capacité de généralisation.
Un autre domaine de recherche actif est l’aspect computationnel de la dimension VC. Bien que la dimension VC fournisse des garanties théoriques, le calcul ou même l’approximation de la dimension VC pour des classes d’hypothèses arbitraires est souvent intractable. Des algorithmes efficaces pour estimer la dimension VC, en particulier pour des modèles à grande échelle ou de haute dimension, sont très recherchés. Cela a des implications pour la sélection de modèles, la régularisation et la conception d’algorithmes d’apprentissage capables de contrôler de manière adaptative la complexité des modèles.
La relation entre la dimension VC et d’autres mesures de complexité, telles que la complexité de Rademacher, les nombres de couverture et la stabilité algorithmique, présente également un terrain fertile pour l’exploration. À mesure que les modèles d’apprentissage deviennent plus sophistiqués, comprendre comment ces différentes mesures interagissent et lesquelles sont les plus prédictives de la généralisation en pratique est un problème ouvert clé. Ceci est particulièrement pertinent dans le contexte des modèles surparamétrés, où la théorie VC classique peut ne pas expliquer pleinement les phénomènes de généralisation observés.
De plus, l’avènement des préoccupations en matière de confidentialité des données et d’équité introduit de nouvelles dimensions à la théorie VC. Les chercheurs explorent comment des contraintes telles que la confidentialité différentielle ou les exigences d’équité affectent la dimension VC et, par conséquent, l’apprentissage des classes d’hypothèses sous ces contraintes. Cette intersection de la théorie VC avec les considérations éthiques et légales est susceptible de prendre de l’importance à mesure que les systèmes d’apprentissage automatique sont de plus en plus déployés dans des domaines sensibles.
Enfin, le développement continu de l’informatique quantique et ses applications potentielles dans l’apprentissage automatique soulèvent des questions sur la dimension VC dans les espaces d’hypothèses quantiques. Comprendre comment les ressources quantiques affectent la capacité et la généralisation des algorithmes d’apprentissage est un domaine d’enquête théorique émergent.
À mesure que le domaine évolue, des organisations telles que l’Association pour l’Avancement de l’Intelligence Artificielle et l’Institut de Statistiques Mathématiques continuent de soutenir la recherche et la diffusion des avancées en théorie VC, garantissant que les questions fondamentales restent au premier plan de la recherche en apprentissage automatique.
Sources & Références