Demistificare la Dimensione Vapnik–Chervonenkis: La Chiave per Comprendere la Complessità e la Generalizzazione dei Modelli nel Machine Learning. Scopri Come la Dimensione VC Forma i Confini di Ciò che gli Algoritmi Possono Apprendere.
- Introduzione alla Dimensione Vapnik–Chervonenkis
- Origini Storiche e Fondamenti Teorici
- Definizione Formale e Quadro Matematico
- Dimensione VC nella Classificazione Binaria
- Frantumazione, Funzioni di Crescita e la Loro Importanza
- Dimensione VC e Capacità del Modello: Implicazioni Pratiche
- Collegamenti all’Overfitting e ai Limiti di Generalizzazione
- Dimensione VC negli Algoritmi di Machine Learning del Mondo Reale
- Limitazioni e Critiche della Dimensione VC
- Direzioni Future e Problemi Aperte nella Teoria VC
- Fonti e Riferimenti
Introduzione alla Dimensione Vapnik–Chervonenkis
La dimensione Vapnik–Chervonenkis (dimensione VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, introdotto da Vladimir Vapnik e Alexey Chervonenkis nei primi anni ’70. Fornisce un quadro matematico rigoroso per quantificare la capacità o la complessità di un insieme di funzioni (classe di ipotesi) in termini della sua abilità di classificare punti dati. La dimensione VC è definita come il numero massimo di punti che possono essere frantumati (cioè, correttamente classificati in tutti i modi possibili) dalla classe di ipotesi. Questo concetto è centrale per comprendere la capacità di generalizzazione degli algoritmi di apprendimento, poiché collega l’espressività di un modello al suo rischio di overfitting.
In termini più formali, se una classe di ipotesi può frantumare un insieme di n punti, ma non può frantumare alcun insieme di n+1 punti, allora la sua dimensione VC è n. Ad esempio, la classe di classificatori lineari nello spazio bidimensionale ha una dimensione VC di 3, il che significa che può frantumare qualsiasi insieme di tre punti, ma non tutti gli insiemi di quattro punti. La dimensione VC serve quindi come misura della ricchezza di una classe di ipotesi, indipendentemente dalla specifica distribuzione dei dati.
L’importanza della dimensione VC risiede nel suo ruolo nel fornire garanzie teoriche per gli algoritmi di machine learning. È un componente chiave nella derivazione dei limiti sull’errore di generalizzazione, che è la differenza tra l’errore sui dati di addestramento e l’errore atteso su dati non visti. L’acclamata disuguaglianza VC, ad esempio, collega la dimensione VC alla probabilità che il rischio empirico (errore di addestramento) devii dal rischio vero (errore di generalizzazione). Questa relazione sostiene il principio di minimizzazione del rischio strutturale, una pietra miliare della moderna teoria dell’apprendimento statistico, che mira a bilanciare la complessità del modello e l’errore di addestramento per raggiungere una generalizzazione ottimale.
Il concetto di dimensione VC è stato ampiamente adottato nell’analisi di vari algoritmi di apprendimento, tra cui macchine a vettori di supporto, reti neurali e alberi decisionali. È anche fondamentale nello sviluppo del framework di apprendimento Probabilmente Approssimativamente Corretto (PAC), che formalizza le condizioni sotto le quali ci si può aspettare che un algoritmo di apprendimento funzioni bene. I principi teorici forniti dalla dimensione VC sono stati fondamentali per l’avanzamento del campo del machine learning e sono riconosciuti da importanti istituzioni di ricerca come Institute for Advanced Study e l’Associazione per l’Avanzamento dell’Intelligenza Artificiale.
Origini Storiche e Fondamenti Teorici
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, introdotto nei primi anni ’70 da Vladimir Vapnik e Alexey Chervonenkis. Il loro lavoro pionieristico è emerso dall’Istituto delle Scienze del Controllo dell’Accademia Russa delle Scienze, dove cercavano di formalizzare i principi sottostanti il riconoscimento dei modelli e il machine learning. La dimensione VC fornisce un quadro matematico rigoroso per quantificare la capacità di un insieme di funzioni (classe di ipotesi) di adattarsi ai dati, il che è cruciale per comprendere la capacità di generalizzazione degli algoritmi di apprendimento.
Nel suo core, la dimensione VC misura il numero massimo di punti che possono essere frantumati (cioè, correttamente classificati in tutti i modi possibili) da una classe di ipotesi. Se una classe di funzioni può frantumare un insieme di dimensione d ma non d+1, la sua dimensione VC è d. Questo concetto consente ai ricercatori di analizzare il compromesso tra complessità del modello e rischio di overfitting, una preoccupazione centrale nel machine learning. L’introduzione della dimensione VC ha segnato un significativo progresso rispetto ad approcci precedenti, meno formali, alla teoria dell’apprendimento, fornendo un ponte tra le prestazioni empiriche e le garanzie teoriche.
I fondamenti teorici della dimensione VC sono strettamente legati allo sviluppo del framework di apprendimento Probabilmente Approssimativamente Corretto (PAC), che formalizza le condizioni sotto le quali ci si può aspettare che un algoritmo di apprendimento funzioni bene su dati non visti. La dimensione VC funge da parametro chiave nei teoremi che limitano l’errore di generalizzazione dei classificatori, stabilendo che una dimensione VC finita è necessaria per l’apprendibilità nel senso PAC. Questo approfondimento ha avuto un profondo impatto sul design e l’analisi degli algoritmi in campi che vanno dalla visione artificiale all’elaborazione del linguaggio naturale.
Il lavoro di Vapnik e Chervonenkis ha gettato le basi per lo sviluppo delle macchine a vettori di supporto e altri metodi basati su kernal, che si basano sui principi di controllo della capacità e minimizzazione del rischio strutturale. I loro contributi sono stati riconosciuti da importanti organizzazioni scientifiche, e la dimensione VC rimane un argomento centrale nel curriculum dei corsi avanzati di machine learning e statistica in tutto il mondo. L’ American Mathematical Society e l’Associazione per l’Avanzamento dell’Intelligenza Artificiale sono tra le organizzazioni che hanno evidenziato l’importanza di questi avanzamenti teorici nelle loro pubblicazioni e conferenze.
Definizione Formale e Quadro Matematico
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, che fornisce una misura rigorosa della capacità o complessità di un insieme di funzioni (classe di ipotesi) in termini della sua capacità di classificare punti dati. Formalmente, la dimensione VC è definita per una classe di funzioni indicatrici (o insiemi) come il numero massimo di punti che possono essere frantumati dalla classe. “Frantumare” un insieme di punti significa che, per ogni possibile etichettatura di quei punti, esiste una funzione nella classe che assegna correttamente quelle etichette.
Siano H una classe di ipotesi di funzioni a valori binari che mappano da uno spazio di input X a {0,1}. Un insieme di punti S = {x₁, x₂, …, xₙ} è detto essere frantumato da H se, per ogni possibile sottoinsieme A di S, esiste una funzione h ∈ H tale che h(x) = 1 se e solo se x ∈ A. La dimensione VC di H, denotata VC(H), è la cardinalità massima n tale che esiste un insieme di n punti in X frantumati da H. Se insiemi finiti arbitrariamente grandi possono essere frantumati, la dimensione VC è infinita.
Matematicamente, la dimensione VC fornisce un ponte tra l’espressività di una classe di ipotesi e la sua capacità di generalizzazione. Una dimensione VC più alta indica una classe più espressiva, capace di adattarsi a schemi più complessi, ma anche a un maggiore rischio di overfitting. Al contrario, una dimensione VC più bassa suggerisce un’espressività limitata e una potenziale migliore generalizzazione, ma possibilmente a scapito di underfitting. La dimensione VC è centrale per la derivazione dei limiti di generalizzazione, come quelli formalizzati nei teoremi fondamentali della teoria dell’apprendimento statistico, che collegano la dimensione VC alla complessità campionaria necessaria per l’apprendimento con una data accuratezza e confidenza.
Il concetto è stato introdotto da Vladimir Vapnik e Alexey Chervonenkis negli anni ’70 e sostiene l’analisi teorica degli algoritmi di apprendimento, incluse le macchine a vettori di supporto e le strutture di minimizzazione del rischio empirico. La dimensione VC è ampiamente riconosciuta e utilizzata nel campo del machine learning ed è discussa in dettaglio da organizzazioni come l’Istituto di Statistica Matematica e l’Associazione per l’Avanzamento dell’Intelligenza Artificiale, entrambi riconosciuti come autorità nel campo della ricerca statistica e dell’intelligenza artificiale, rispettivamente.
Dimensione VC nella Classificazione Binaria
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, particolarmente rilevante per l’analisi dei modelli di classificazione binaria. Introdotta da Vladimir Vapnik e Alexey Chervonenkis nei primi anni ’70, la dimensione VC quantifica la capacità o complessità di un insieme di funzioni (classe di ipotesi) misurando la sua abilità di frantumare insiemi finiti di punti dati. Nel contesto della classificazione binaria, “frantumare” si riferisce alla capacità di un classificatore di etichettare correttamente tutte le possibili assegnazioni di etichette binarie (0 o 1) a un dato insieme di punti.
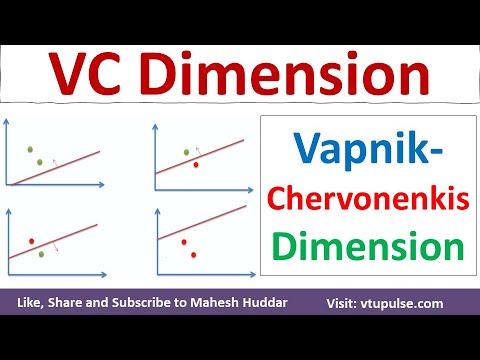
Formalmente, la dimensione VC di una classe di ipotesi è il numero massimo di punti che possono essere frantumati da quella classe. Ad esempio, consideriamo la classe di classificatori lineari (perceptron) in uno spazio bidimensionale. Questa classe può frantumare qualsiasi insieme di tre punti in posizione generale, ma non tutti gli insiemi di quattro punti. Pertanto, la dimensione VC dei classificatori lineari in due dimensioni è tre. La dimensione VC fornisce una misura dell’espressività di un modello: una dimensione VC più alta indica un modello più flessibile che può adattarsi a schemi più complessi, ma aumenta anche il rischio di overfitting.
Nella classificazione binaria, la dimensione VC gioca un ruolo cruciale nel comprendere il compromesso tra complessità del modello e generalizzazione. Secondo la teoria, se la dimensione VC è troppo alta rispetto al numero di campioni di addestramento, il modello può adattarsi perfettamente ai dati di addestramento ma fallire nella generalizzazione a dati non visti. Al contrario, un modello con una bassa dimensione VC può sottostimare, non riuscendo a catturare schemi importanti nei dati. La dimensione VC fornisce quindi garanzie teoriche sull’errore di generalizzazione, come formalizzato nella disuguaglianza VC e nei limiti correlati.
Il concetto di dimensione VC è centrale nello sviluppo degli algoritmi di apprendimento e nell’analisi delle loro prestazioni. Sostiene il framework di apprendimento Probabilmente Approssimativamente Corretto (PAC), che caratterizza le condizioni sotto le quali un algoritmo di apprendimento può raggiungere un basso errore di generalizzazione con alta probabilità. La dimensione VC è utilizzata anche nel design e nell’analisi delle macchine a vettori di supporto (SVM), una classe ampiamente utilizzata di classificatori binari, così come nello studio delle reti neurali e di altri modelli di machine learning.
L’importanza della dimensione VC nella classificazione binaria è riconosciuta da importanti istituzioni di ricerca e organizzazioni nel campo dell’intelligenza artificiale e del machine learning, come l’Associazione per l’Avanzamento dell’Intelligenza Artificiale e l’Associazione per le Macchine di Calcolo. Queste organizzazioni supportano la ricerca e la divulgazione di concetti fondamentali come la dimensione VC, che continua a plasmare le basi teoriche e le applicazioni pratiche del machine learning.
Frantumazione, Funzioni di Crescita e la Loro Importanza
I concetti di frantumazione e funzioni di crescita sono centrali per comprendere la dimensione Vapnik–Chervonenkis (VC), una misura fondamentale nella teoria dell’apprendimento statistico. La dimensione VC, introdotta da Vladimir Vapnik e Alexey Chervonenkis, quantifica la capacità di un insieme di funzioni (classe di ipotesi) di adattarsi ai dati ed è cruciale per analizzare la capacità di generalizzazione degli algoritmi di apprendimento.
Frantumare si riferisce alla capacità di una classe di ipotesi di classificare perfettamente tutte le possibili etichettature di un insieme finito di punti. Formalmente, un insieme di punti si dice frantumato da una classe di ipotesi se, per ogni possibile assegnazione di etichette binarie ai punti, esiste una funzione nella classe che separa correttamente i punti secondo quelle etichette. Ad esempio, nel caso dei classificatori lineari in due dimensioni, qualsiasi insieme di tre punti non collineari può essere frantumato, ma non tutti gli insiemi di quattro punti possono esserlo.
La funzione di crescita, nota anche come coefficiente di frantumazione, misura il numero massimo di etichettature distinte (dichotomie) che una classe di ipotesi può realizzare su un qualsiasi insieme di n punti. Se la classe di ipotesi può frantumare ogni insieme di n punti, la funzione di crescita è uguale a 2n. Tuttavia, man mano che n aumenta, la maggior parte delle classi di ipotesi raggiunge un punto in cui non possono più frantumare tutte le etichettature possibili, e la funzione di crescita aumenta più lentamente. La dimensione VC è definita come il più grande intero d tale che la funzione di crescita è uguale a 2d; in altre parole, è la dimensione del più grande insieme che può essere frantumato dalla classe di ipotesi.
Questi concetti sono significativi perché forniscono un modo rigoroso per analizzare la complessità e il potere espressivo dei modelli di apprendimento. Una dimensione VC più alta indica un modello più espressivo, capace di adattarsi a schemi più complessi, ma anche a un maggiore rischio di overfitting. Al contrario, una bassa dimensione VC suggerisce una capacità limitata, che potrebbe portare a un underfitting. La dimensione VC è direttamente collegata ai limiti di generalizzazione: aiuta a determinare quanta data di addestramento è necessaria per garantire che le prestazioni del modello sui dati non visti saranno simili alle sue prestazioni sul set di addestramento. Questa relazione è formalizzata in teoremi come il teorema fondamentale della teoria dell’apprendimento statistico, che sostiene gran parte della moderna teoria del machine learning.
Lo studio della frantumazione e delle funzioni di crescita, e la loro connessione con la dimensione VC, è fondamentale nel lavoro di organizzazioni come l’Associazione per l’Avanzamento dell’Intelligenza Artificiale e l’Istituto di Statistica Matematica, che promuovono la ricerca e la divulgazione degli avanzamenti nella teoria dell’apprendimento statistico e delle sue applicazioni.
Dimensione VC e Capacità del Modello: Implicazioni Pratiche
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, fornendo una misura rigorosa della capacità o complessità di un insieme di funzioni (classe di ipotesi) che un modello di machine learning può implementare. In termini pratici, la dimensione VC quantifica il numero massimo di punti che possono essere frantumati (cioè, correttamente classificati in tutti i modi possibili) dal modello. Questa misura è cruciale per comprendere il compromesso tra la capacità di un modello di adattarsi ai dati di addestramento e la sua capacità di generalizzare a dati non visti.
Una dimensione VC più alta indica una classe di modelli più espressiva, capace di rappresentare schemi più complessi. Ad esempio, un classificatore lineare in uno spazio bidimensionale ha una dimensione VC di 3, il che significa che può frantumare qualsiasi insieme di tre punti ma non tutti gli insiemi di quattro. Al contrario, modelli più complessi, come le reti neurali con molti parametri, possono avere dimensioni VC molto più alte, riflettendo la loro maggiore capacità di adattarsi a dataset diversi.
Le implicazioni pratiche della dimensione VC sono più evidenti nel contesto di overfitting e underfitting. Se la dimensione VC di un modello è molto più grande del numero di campioni di addestramento, il modello potrebbe sovra-adattarsi, memorizzando i dati di addestramento piuttosto che apprendere schemi generalizzabili. Al contrario, se la dimensione VC è troppo bassa, il modello potrebbe sottostimare, non riuscendo a catturare la struttura sottostante dei dati. Pertanto, selezionare un modello con una dimensione VC appropriata rispetto alla dimensione del dataset è essenziale per ottenere buone prestazioni di generalizzazione.
La dimensione VC sostiene anche garanzie teoriche nella teoria dell’apprendimento, come il framework di apprendimento Probabilmente Approssimativamente Corretto (PAC). Fornisce limiti sul numero di campioni di addestramento necessari per garantire che il rischio empirico (errore sul set di addestramento) sia vicino al rischio vero (errore atteso su nuovi dati). Questi risultati guidano i professionisti nella stima della complessità campionaria necessaria per un apprendimento affidabile, specialmente in applicazioni ad alto rischio come la diagnosi medica o i sistemi autonomi.
Nella pratica, sebbene la dimensione VC esatta sia spesso difficile da calcolare per i modelli complessi, il suo ruolo concettuale informa il design e la selezione degli algoritmi. Tecniche di regolarizzazione, criteri di selezione del modello e strategie di validazione incrociata sono tutte influenzate dai principi sottostanti al controllo della capacità articolati dalla dimensione VC. Il concetto è stato introdotto da Vladimir Vapnik e Alexey Chervonenkis, il cui lavoro ha gettato le basi per la moderna teoria dell’apprendimento statistico e continua ad influenzare la ricerca e le applicazioni nel machine learning (Istituto di Statistica Matematica).
Collegamenti all’Overfitting e ai Limiti di Generalizzazione
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, influenzando direttamente la nostra comprensione dell’overfitting e della generalizzazione nei modelli di machine learning. La dimensione VC quantifica la capacità o complessità di un insieme di funzioni (classe di ipotesi) misurando il numero massimo di punti che possono essere frantumati—cioè, correttamente classificati in tutti i modi possibili—dalle funzioni nella classe. Questa misura è cruciale per analizzare quanto bene un modello addestrato su un dataset finito performerà su dati non visti, una proprietà nota come generalizzazione.
L’overfitting si verifica quando un modello apprende non solo gli schemi sottostanti ma anche il rumore nei dati di addestramento, risultando in scarse prestazioni su nuovi dati. La dimensione VC fornisce un quadro teorico per comprendere e mitigare l’overfitting. Se la dimensione VC di una classe di ipotesi è molto più grande del numero di campioni di addestramento, il modello ha sufficienti capacità per adattarsi al rumore casuale, aumentando il rischio di overfitting. Al contrario, se la dimensione VC è troppo bassa, il modello potrebbe sottostimare, non riuscendo a catturare la struttura essenziale dei dati.
La relazione tra dimensione VC e generalizzazione è formalizzata attraverso limiti di generalizzazione. Questi limiti, come quelli derivati dal lavoro fondamentale di Vladimir Vapnik e Alexey Chervonenkis, affermano che con alta probabilità, la differenza tra il rischio empirico (errore sul set di addestramento) e il rischio vero (errore atteso su nuovi dati) è piccola se il numero di campioni di addestramento è sufficientemente grande rispetto alla dimensione VC. In particolare, l’errore di generalizzazione diminuisce man mano che il numero di campioni aumenta, a patto che la dimensione VC rimanga fissa. Questa intuizione sostiene il principio che modelli più complessi (con dimensione VC più alta) richiedono più dati per generalizzare bene.
- La dimensione VC è centrale per la teoria della convergenza uniforme, che garantisce che le medie empiriche convergano a valori attesi uniformemente su tutte le funzioni nella classe di ipotesi. Questa proprietà è essenziale per garantire che minimizzare l’errore sul set di addestramento porti a un basso errore su dati non visti.
- Il concetto è anche integrale allo sviluppo della minimizzazione del rischio strutturale, una strategia che bilancia complessità del modello e errore di addestramento per ottenere una generalizzazione ottimale, come formalizzato nella teoria delle macchine a vettori di supporto e di altri algoritmi di apprendimento.
L’importanza della dimensione VC nella comprensione dell’overfitting e della generalizzazione è riconosciuta da importanti istituzioni di ricerca ed è fondamentale nel curriculum della teoria dell’apprendimento statistico, come delineato da organizzazioni come l’ Institute for Advanced Study e l’Associazione per l’Avanzamento dell’Intelligenza Artificiale. Queste organizzazioni contribuiscono allo sviluppo e alla divulgazione continui degli avanzamenti teorici nel machine learning.
Dimensione VC negli Algoritmi di Machine Learning del Mondo Reale
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, fornendo una misura rigorosa della capacità o complessità di un insieme di funzioni (classe di ipotesi) che un algoritmo di machine learning può implementare. Nei machine learning del mondo reale, la dimensione VC gioca un ruolo cruciale nella comprensione della capacità di generalizzazione degli algoritmi—quanto bene un modello addestrato su un campione finito è atteso a performare su dati non visti.
In termini pratici, la dimensione VC aiuta a quantificare il compromesso tra complessità del modello e rischio di overfitting. Ad esempio, un classificatore lineare in uno spazio bidimensionale (come un perceptron) ha una dimensione VC di 3, il che significa che può frantumare qualsiasi insieme di tre punti ma non tutti gli insiemi di quattro. Modelli più complessi, come le reti neurali, possono avere dimensioni VC molto più elevate, riflettendo la loro capacità di adattarsi a schemi più intricati nei dati. Tuttavia, una dimensione VC più alta aumenta anche il rischio di overfitting, dove il modello cattura il rumore piuttosto che la struttura sottostante.
La dimensione VC è particolarmente rilevante nel contesto del framework di apprendimento Probabilmente Approssimativamente Corretto (PAC), che fornisce garanzie teoriche sul numero di campioni di addestramento necessari per raggiungere un livello desiderato di precisione e confidenza. Secondo la teoria, la complessità campionaria—il numero di esempi necessari per l’apprendimento—cresce con la dimensione VC della classe di ipotesi. Questa relazione guida i professionisti nella selezione di classi di modelli e strategie di regolarizzazione appropriate per bilanciare espressività e generalizzazione.
Nelle applicazioni del mondo reale, la dimensione VC informa il design e la valutazione di algoritmi come le macchine a vettori di supporto (SVM), gli alberi decisionali e le reti neurali. Ad esempio, le SVM sono strettamente collegate alla teoria VC, poiché il loro principio di massimizzazione del margine può essere interpretato come un modo per controllare la dimensione VC effettiva del classificatore, migliorando così le prestazioni di generalizzazione. Allo stesso modo, le tecniche di potatura negli alberi decisionali possono essere viste come metodi per ridurre la dimensione VC e mitigare l’overfitting.
Sebbene la dimensione VC esatta di modelli complessi come le reti neurali profonde sia spesso difficile da calcolare, il concetto rimane influente nel guidare la ricerca e la pratica. Sostiene lo sviluppo di metodi di regolarizzazione, criteri di selezione del modello e limiti teorici sulle prestazioni di apprendimento. La rilevanza duratura della dimensione VC si riflette nel suo ruolo fondamentale nel lavoro di organizzazioni come l’Associazione per l’Avanzamento dell’Intelligenza Artificiale e l’Associazione per le Macchine di Calcolo, che promuovono la ricerca nella teoria del machine learning e le sue implicazioni pratiche.
Limitazioni e Critiche della Dimensione VC
La dimensione Vapnik–Chervonenkis (VC) è un concetto fondamentale nella teoria dell’apprendimento statistico, fornendo una misura della capacità o complessità di un insieme di funzioni (classe di ipotesi) in termini della sua abilità di frantumare punti dati. Nonostante la sua importanza teorica, la dimensione VC ha diverse limitazioni notevoli ed è stata oggetto di varie critiche nelle comunità di machine learning e statistica.
Una limitazione principale della dimensione VC è la sua attenzione ai casi peggiori. La dimensione VC quantifica il più grande insieme di punti che può essere frantumato da una classe di ipotesi, ma questo non sempre riflette le prestazioni tipiche o medie degli algoritmi di apprendimento in contesti pratici. Di conseguenza, la dimensione VC può sovrastimare la vera complessità richiesta per una generalizzazione di successo nei dati del mondo reale, dove le distribuzioni sono spesso molto lontane da quelle avversarie o nei casi peggiori. Questo scollamento può portare a limiti eccessivamente pessimisti sulla complessità campionaria e sull’errore di generalizzazione.
Un’altra critica riguardo l’applicabilità della dimensione VC ai modelli di machine learning moderni, particolarmente alle reti neurali profonde. Sebbene la dimensione VC sia ben definita per classi di ipotesi semplici come i classificatori lineari o gli alberi decisionali, diventa difficile da calcolare o persino da interpretare in modo significativo per modelli altamente parametrizzati. In molti casi, le reti profonde possono avere dimensioni VC estremamente alte o addirittura infinite, eppure generalizzare bene in pratica. Questo fenomeno, talvolta definito “paradosso della generalizzazione”, suggerisce che la dimensione VC non cattura pienamente i fattori che governano la generalizzazione nei sistemi di machine learning contemporanei.
Inoltre, la dimensione VC è fondamentalmente una misura combinatoria, ignorando la geometria e la struttura della distribuzione dei dati. Non tiene conto delle proprietà basate sul margine, della regolarizzazione o di altre tecniche algoritmiche che possono influenzare significativamente la generalizzazione. Misure di complessità alternative, come la complessità di Rademacher o i numeri di copertura, sono state proposte per affrontare alcune di queste carenze incorporando aspetti legati ai dati o geometrici.
Infine, la dimensione VC presuppone che i punti dati siano indipendenti e identicamente distribuiti (i.i.d.), un’assunzione che potrebbe non reggere in molte applicazioni del mondo reale, come l’analisi delle serie temporali o i compiti di previsione strutturata. Questo limita ulteriormente l’applicabilità diretta della teoria basata sulla VC in alcuni domini.
Nonostante queste limitazioni, la dimensione VC rimane una pietra miliare della teoria dell’apprendimento, fornendo intuizioni preziose sui limiti fondamentali dell’apprendibilità. La ricerca continua da parte di organizzazioni come l’Associazione per l’Avanzamento dell’Intelligenza Artificiale e l’Istituto di Statistica Matematica continua a esplorare estensioni e alternative al framework VC, mir andando a meglio allineare le garanzie teoriche con le osservazioni empiriche nel machine learning moderno.
Direzioni Future e Problemi Aperte nella Teoria VC
La dimensione Vapnik–Chervonenkis (VC) rimane una pietra miliare della teoria dell’apprendimento statistico, fornendo una misura rigorosa della capacità delle classi di ipotesi e della loro capacità di generalizzare a partire da campioni finiti. Nonostante il suo ruolo fondamentale, diverse direzioni future e problemi aperti continuano a guidare la ricerca nella teoria VC, riflettendo sia sfide teoriche che domande pratiche nel machine learning moderno.
Una direzione prominente è l’estensione della teoria VC a domini di dati più complessi e strutturati. L’analisi tradizionale della dimensione VC è ben adatta per la classificazione binaria e spazi di ipotesi semplici, ma le applicazioni moderne spesso comportano output multi-classe, strutturati o dati con intricate dipendenze. Sviluppare nozioni generalizzate di dimensione VC che possano catturare la complessità delle reti neurali profonde, delle architetture ricorrenti e di altri modelli avanzati rimane una sfida aperta. Questo include comprendere la capacità effettiva di questi modelli e come si relaziona alle loro prestazioni empiriche e capacità di generalizzazione.
Un altro area attiva di ricerca riguarda l’aspetto computazionale della dimensione VC. Sebbene la dimensione VC fornisca garanzie teoriche, calcolare o persino approssimare la dimensione VC per classi di ipotesi arbitrari è spesso impraticabile. Algoritmi efficienti per stimare la dimensione VC, specialmente per modelli su larga scala o ad alta dimensione, sono molto ricercati. Questo ha implicazioni per la selezione del modello, la regolarizzazione e il design di algoritmi di apprendimento che possono controllare adattativamente la complessità del modello.
La relazione tra dimensione VC e altre misure di complessità, come la complessità di Rademacher, i numeri di copertura e la stabilità algoritmica, presenta anche un terreno fertile per l’esplorazione. Man mano che i modelli di machine learning diventano più sofisticati, comprendere come queste diverse misure interagiscono e quali sono le più predittive della generalizzazione nella pratica è un problema chiave aperto. Questo è particolarmente rilevante nel contesto di modelli sovra-parametrizzati, dove la teoria VC classica potrebbe non spiegare pienamente i fenomeni di generalizzazione osservati.
Inoltre, l’avvento di questioni di privacy dei dati e di equità introduce nuove dimensioni alla teoria VC. I ricercatori stanno indagando su come vincoli come la privacy differenziale o i requisiti di equità influenzino la dimensione VC e, di conseguenza, l’apprendibilità delle classi di ipotesi sotto questi vincoli. Questa intersezione tra la teoria VC e considerazioni etiche e legali è destinata a crescere in importanza man mano che i sistemi di machine learning vengono sempre più implementati in domini sensibili.
Infine, lo sviluppo continuo del calcolo quantistico e le sue potenziali applicazioni nel machine learning sollevano domande sulla dimensione VC negli spazi ipotetici quantistici. Comprendere come le risorse quantistiche influenzano la capacità e la generalizzazione degli algoritmi di apprendimento è un’area emergente di indagine teorica.
Man mano che il campo evolve, organizzazioni come l’Associazione per l’Avanzamento dell’Intelligenza Artificiale e l’Istituto di Statistica Matematica continuano a supportare la ricerca e la divulgazione degli avanzamenti nella teoria VC, garantendo che le questioni fondamentali rimangano in prima linea nella ricerca sul machine learning.
Fonti e Riferimenti