バプニク–チェルヴォネンキス次元の解明:モデルの複雑性と一般化を理解するための鍵。VC次元がアルゴリズムの学習可能性の境界をどのように形成するかを発見しましょう。
- バプニク–チェルヴォネンキス次元の紹介
- 歴史的起源と理論的基盤
- 定義と数学的枠組み
- バイナリ分類におけるVC次元
- シャタリング、成長関数、その重要性
- VC次元とモデルの容量:実務上の意味
- 過学習と一般化境界への関連
- 実世界の機械学習アルゴリズムにおけるVC次元
- VC次元の限界と批評
- VC理論の将来の方向性と未解決問題
- 出典・参考文献
バプニク–チェルヴォネンキス次元の紹介
バプニク–チェルヴォネンキス次元(VC次元)は、1970年代初頭にウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入された統計学習理論の基本概念です。これは、データポイントを分類する能力に関して、一連の関数(仮説クラス)のキャパシティや複雑さを定量化するための厳密な数学的枠組みを提供します。 VC次元は、仮説クラスによって「シャタリング」され得る(つまり、すべての可能な方法で正しく分類される)点の最大数として定義されます。この概念は、モデルの表現可能性を過学習のリスクに結びつけるため、学習アルゴリズムの一般化能力を理解する上で中心的な役割を果たします。
より形式的に言えば、仮説クラスがn個の点の集合をシャタリングできる場合、しかしn+1個の点の集合をシャタリングできない場合、そのVC次元はnと定義されます。例えば、2次元空間の線形分類器のクラスは、3つの点のセットをシャタリングできることを意味し、4つの点の全てのセットをシャタリングすることはできません。したがって、VC次元は仮説クラスの豊富さの尺度として機能し、特定のデータ分布には依存しません。
VC次元の重要性は、機械学習アルゴリズムに対する理論的保証を提供する役割にあります。これは、訓練データ上の誤差と未知のデータ上の期待誤差との差を示す一般化誤差の上限を導出する際の重要な要素です。気になるVC不等式は、経験リスク(訓練誤差)と真のリスク(一般化誤差)の間の関係をVC次元に関連付けます。この関係は、モデルの複雑性と訓練誤差のバランスを取って最適な一般化を達成することを目指す構造リスク最小化の原則を支える基盤です。
VC次元の概念は、サポートベクトルマシン、ニューラルネットワーク、決定木など、さまざまな学習アルゴリズムの分析に広く採用されています。また、学習アルゴリズムが良好に機能する予測取引の条件を形式化した「確率的におおよそ正しい(PAC)」学習の枠組みの発展にも基礎的です。VC次元が提供する理論的基盤は、機械学習分野の進歩に不可欠であり、先端研究所や人工知能の進歩協会などの主要な研究機関に認識されています。
歴史的起源と理論的基盤
バプニク–チェルヴォネンキス(VC)次元は、1970年代初頭にウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入された統計学習理論の基本概念です。彼らの画期的な研究は、ロシア科学アカデミーの制御科学所から生まれ、パターン認識と機械学習の原理を形式化しようとしました。VC次元は、一連の関数(仮説クラス)がデータにフィットする能力を定量化するための厳密な数学的枠組みを提供し、学習アルゴリズムの一般化能力を理解する上で重要です。
VC次元の本質は、仮説クラスがシャタリング可能な点の最大数を測定することにあります。もしある関数のクラスがサイズdのセットをシャタリングできるが、d+1のセットをシャタリングできない場合、そのVC次元はdです。この概念は、モデルの複雑性と過学習のリスクとのトレードオフを分析するために研究者が用いることを可能にします。VC次元の導入は、以前のあまり形式化されていない学習理論に対する重大な進展を示しており、経験的パフォーマンスと理論的保証の橋渡しを提供します。
VC次元の理論的基盤は、未見のデータに対して学習アルゴリズムが良好に動作する条件を形式化した「確率的におおよそ正しい(PAC)」学習の枠組みの発展に密接に関連しています。VC次元は、分類器の一般化誤差を制約する定理における重要なパラメータとして機能し、有限のVC次元がPAC意味での学習可能性に必要であることを確立します。この洞察は、コンピュータビジョンや自然言語処理などの分野におけるアルゴリズムの設計および分析に深い影響を与えました。
バプニクとチェルヴォネンキスの研究は、サポートベクトルマシンやその他のカーネルベースの手法の発展の基盤を築き、キャパシティ制御と構造リスク最小化の原則に依存しています。彼らの貢献は、主要な科学機関によって認識され、VC次元は世界中の高等機械学習や統計コースのカリキュラムの中心的なテーマのままです。アメリカ数学会や人工知能の進歩協会は、彼らの出版物や会議でこれらの理論的進展の重要性を強調しています。
定義と数学的枠組み
バプニク–チェルヴォネンキス(VC)次元は、統計学習理論の基本概念であり、データポイントを分類する能力に関して、一連の関数(仮説クラス)のキャパシティまたは複雑さを厳密に測定します。形式的には、VC次元は指定された指示関数(または集合)のクラスについて、クラスによってシャタリング可能な点の最大数として定義されます。「シャタリング」とは、与えられたポイントのすべての可能なラベリングに対して、そのラベルを正しく割り当てる関数がクラスに存在することを意味します。
Hを入力空間Xから{0,1}への二値関数の仮説クラスとします。ポイントの集合S = {x₁, x₂, …, xₙ}がHによってシャタリングされると言われるのは、すべての可能な部分集合Aに対して、h ∈ Hという関数が存在し、h(x) = 1ならば、x ∈ Aとなる場合です。HのVC次元、すなわちVC(H)は、Xの中でHによってシャタリングされるn個の点の集合が存在する最大の基数nです。無限のサイズの有限セットがシャタリング可能である場合、VC次元は無限です。
数学的に言えば、VC次元は仮説クラスの表現力と一般化能力との間の橋渡しを提供します。高いVC次元は、より複雑なパターンに適応できるより表現力のあるクラスを示しますが、過学習のリスクも高まります。反対に、低いVC次元は限られた表現力を示し、一般化は良好である可能性がありますが、データの重要なパターンを捉えられない可能性があります。VC次元は、特定の精度と信頼度での学習に必要なサンプルの複雑性を関連付ける、統計学習理論の基本定理において中心的な役割を果たします。
この概念は、1970年代にウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入され、サポートベクトルマシンや経験的リスク最小化フレームワークを含む学習アルゴリズムの理論的分析の基盤となっています。VC次元は広く認識され、統計と人工知能の研究における権威ある組織である数学統計所や人工知能の進歩協会が詳細に議論しています。
バイナリ分類におけるVC次元
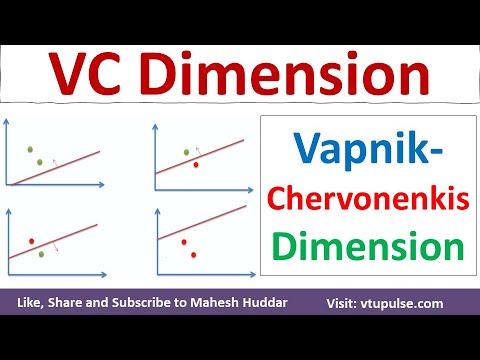
バプニク–チェルヴォネンキス(VC)次元は、特にバイナリ分類モデルの分析に関連する統計学習理論の基本概念です。1970年代初頭にウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入されたVC次元は、有限のデータポイントの集合をシャタリングする能力によって、一連の関数(仮説クラス)の容量または複雑性を定量化します。バイナリ分類の文脈では、「シャタリング」とは、分類器が与えられた点のセットに対してすべての可能なバイナリラベル(0または1)の割り当てを正しくラベリングできる能力を指します。
形式的には、仮説クラスのVC次元は、そのクラスによってシャタリング可能な点の最大数です。たとえば、2次元空間の線形分類器(パーセプトロン)のクラスを考えてみましょう。このクラスは、一般的な位置にある3つの点の集合をシャタリングできますが、4つの点の全ての集合をシャタリングすることはできません。したがって、2次元における線形分類器のVC次元は3です。VC次元はモデルの表現力の尺度を提供します:高いVC次元は、より柔軟なモデルがより複雑なパターンに適合できることを示しますが、過学習のリスクも高まります。
バイナリ分類において、VC次元はモデルの複雑性と一般化の間のトレードオフを理解する上で重要な役割を果たします。理論によれば、VC次元がトレーニングサンプルの数に対して高すぎる場合、モデルはトレーニングデータに完全にフィットするかもしれませんが、未知のデータに対しては一般化できない可能性があります。逆に、VC次元が低すぎるモデルは、フィッティングに失敗し、データの重要なパターンを捉えられないかもしれません。したがって、VC次元は、VC不等式や関連する境界を通じて一般化誤差に対する理論的保証を提供します。
VC次元の概念は、学習アルゴリズムの開発とその性能分析の中心です。VC次元は、低い一般化誤差を高確率で達成できる学習アルゴリズムが機能する条件を特定する確率的におおよそ正しい(PAC)学習フレームワークの基盤を成しています。VC次元は、広く使用されるバイナリ分類器であるサポートベクトルマシン(SVM)の設計と分析にも使用されており、ニューラルネットやその他の機械学習モデルの研究においても重要な役割を果たしています。
バイナリ分類におけるVC次元の重要性は、人工知能と機械学習の分野での主要な研究機関や組織によって認識されています。たとえば、人工知能の進歩協会やコンピュータ機械協会などがそれにあたります。これらの組織は、VC次元のような基本概念の研究と普及を支援し、機械学習の理論的基盤や実用的応用に影響を与え続けています。
シャタリング、成長関数、その重要性
シャタリングと成長関数の概念は、統計学習理論における基本的な尺度であるバプニク–チェルヴォネンキス(VC)次元を理解する上で中心的な役割を果たします。VC次元は、ウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入され、関数の集合(仮説クラス)がデータにフィットする能力を定量化し、学習アルゴリズムの一般化能力を分析する上で重要です。
シャタリングとは、仮説クラスが有限点集合のすべての可能なラベリングを完璧に分類できる能力を指します。正式には、ポイントの集合が仮説クラスによってシャタリングされると言われるのは、すべてのバイナリラベルの割り当てに対して、そのラベルに従ってポイントを正しく分離する関数がクラスに存在する場合です。たとえば、2次元の線形分類器の場合、任意の3つの非共線的なポイントの集合はシャタリング可能ですが、すべての4つのポイントの集合はそうではありません。
成長関数、またはシャタリング係数は、仮説クラスが任意のnポイントの集合で実現可能な異なるラベリング(二分)を最大限に測定します。仮説クラスがnポイントのすべての集合をシャタリングできる場合、成長関数は2nになります。しかし、nが増えるにつれて、ほとんどの仮説クラスはすべての可能なラベリングをシャタリングできなくなるポイントに達し、成長関数の増加は遅くなります。VC次元は、仮説クラスによってシャタリング可能な最大の整数dとして定義され、成長関数が2dに等しくなると解釈できます。
これらの概念は、学習モデルの複雑さと表現力を分析するための厳密な手段を提供するため重要です。高いVC次元は、より表現力のあるモデルがより複雑なパターンに適応できることを示しますが、過学習のリスクも高まります。反対に、低いVC次元は限られた能力を示すため、アンダーフィッティングにつながるかもしれません。VC次元は一般化境界に直接リンクしており、モデルが未見データでの性能を保証するために必要な訓練データの量を決定するのに役立ちます。この関係は、統計学習の基本定理などの定理で形式化され、現代の機械学習理論の多くを支えています。
シャタリングおよび成長関数の研究、そのVC次元との関連性は、人工知能の進歩協会や数学統計所などの組織の仕事において基盤的であり、統計学習理論とその応用の進展を促進しています。
VC次元とモデルの容量:実務上の意味
バプニク–チェルヴォネンキス(VC)次元は、機械学習モデルが実装できる関数の集合(仮説クラス)の容量または複雑さを厳密に測定する基本的な概念です。実務上、VC次元はモデルによってシャタリング可能な最大のポイント数を定量化します。これは、モデルが訓練データにフィットする能力と未知のデータに一般化する能力とのトレードオフを理解するために重要です。
高いVC次元は、より表現力のあるモデルクラスを示し、より複雑なパターンを表現することが可能です。たとえば、2次元空間の線形分類器は、VC次元が3であるため、任意の3つのポイントのセットをシャタリングできますが、すべての4つのセットをシャタリングすることはできません。対照的に、多くのパラメータを持つニューラルネットワークなどの複雑なモデルは、より多くのデータセットにフィットできるので、VC次元がはるかに高くなることがあります。
VC次元の実務上の影響は、過学習とアンダーフィッティングの文脈で特に明らかです。モデルのVC次元がトレーニングサンプルの数よりも大幅に大きい場合、モデルは過学習し、一般化可能なパターンを学ぶ代わりにトレーニングデータを記憶することになります。逆に、VC次元が低すぎる場合、モデルはアンダーフィットし、データの基盤となる構造を捉えない結果になります。したがって、データセットのサイズに対して適切なVC次元を持つモデルを選択することは、良好な一般化性能を達成するために重要です。
VC次元は、確率的におおよそ正しい(PAC)学習フレームワークのような学習理論における理論的保証の基盤を成します。これは、経験リスク(訓練セット上の誤差)が真のリスク(新しいデータ上の期待誤差)に近いことを保証するために必要な訓練サンプルの数に制限を提供します。これらの結果は、医療診断や自律システムのような不可欠な応用において、信頼できる学習のために必要なサンプルの複雑性を見積もる際の指針となります。
実務においては、複雑なモデルの正確なVC次元を計算することはしばしば困難ですが、その概念的役割はアルゴリズムの設計と選択に情報を与えます。正則化手法、モデル選択基準、および交差検証戦略はすべて、VC次元によって説明されるキャパシティ制御の基本原則に影響を受けます。この概念は、ウラジーミル・バプニクとアレクセイ・チェルヴォネンキスによって導入され、その仕事は現代の統計学習理論の基盤を築き、機械学習における研究や応用に影響を与え続けています(数学統計所)。
過学習と一般化境界への関連
バプニク–チェルヴォネンキス(VC)次元は、統計学習理論の基本的な概念であり、機械学習モデルにおける過学習と一般化の理解に直接影響を与えます。VC次元は、仮説クラスの一連の関数によってシャタリングされ得る最大のポイントのセットを測定することで、一連の関数のキャパシティまたは複雑さの尺度を定量化します。この測定は、有限データセットで訓練されたモデルが未見のデータでどれほどよく機能するかを分析するために重要です。この特性は一般化として知られています。
過学習は、モデルが基本的なパターンだけでなくトレーニングデータにおけるノイズも学習してしまうときに発生し、新たに見たデータでのパフォーマンスが悪くなります。VC次元は、過学習を理解し軽減するための理論的枠組みを提供します。仮説クラスのVC次元がトレーニングサンプルの数よりも大幅に大きい場合、モデルはランダムなノイズをフィットできるだけの能力があるため、過学習のリスクが増します。逆に、VC次元が低すぎると、モデルはアンダーフィットし、データの重要な構造を捉えられなくなるかもしれません。
VC次元と一般化の関係は、一般化境界を通じて形式化されます。これらの境界は、ウラジーミル・バプニクとアレクセイ・チェルヴォネンキスの基本的な研究から導出されており、高い確率で、経験リスク(訓練セットの誤差)と真のリスク(新しいデータでの期待される誤差)との間の差が小さいことを示しています。それは、サンプルの数がVC次元に対して十分に大きい場合に成り立ちます。特に、一般化誤差はサンプルの数が増加すると減少し、VC次元が固定されている限りにおいてです。この洞察は、より複雑なモデル(高いVC次元を持つモデル)が良好な一般化のためにより多くのデータを必要とするという原則を支えています。
- VC次元は、経験的平均が仮説クラス内のすべての関数に対して期待値に均一に収束することを保証する理論である一様収束の理論の中心的な役割を果たします。この特性は、訓練セット上の誤差を最小化することが未見データ上での低い誤差に繋がることを保証するために必要です。
- この概念はまた、モデルの複雑さと訓練誤差のバランスを取って最適な一般化を達成するための戦略、すなわち構造リスク最小化の発展に不可欠です。これは、サポートベクトルマシンや他の学習アルゴリズムの理論で形式化されています。
過学習と一般化を理解する上でのVC次元の重要性は、主要な研究機関によって認識されており、統計学習理論のカリキュラムの基礎となっています。これには、先端研究所や人工知能の進歩協会が含まれます。これらの組織は、機械学習における理論的進展の開発と普及に貢献し続けています。
実世界の機械学習アルゴリズムにおけるVC次元
バプニク–チェルヴォネンキス(VC)次元は、機械学習アルゴリズムが実装できる関数の集合の容量または複雑さを厳密に測定する基礎的な概念です。実務上、VC次元はアルゴリズムの一般化能力を理解する上で重要な役割を果たします。それは有限サンプルで訓練されたモデルが知らないデータでどれほどよく機能するかを示します。
実務的には、VC次元はモデルの複雑性と過学習のリスクとのトレードオフを定量化するのに役立ちます。たとえば、2次元空間の線形分類器(パーセプトロン)はVC次元が3であるため、任意の3つのポイントのセットをシャタリング可能ですが、すべての4つのポイントのセットをシャタリングすることはできません。より複雑なモデル、たとえばニューラルネットワークは、データのより複雑なパターンにフィットする能力を示すVC次元がはるかに高くなることがあります。ただし、より高いVC次元は過学習のリスクも高め、モデルがノイズを捕らえる可能性があります。
VC次元は、確率的におおよそ正しい(PAC)学習フレームワークの文脈において特に関連性があり、所望の精度と信頼度を達成するために必要なトレーニングサンプルの数に関する理論的保証を提供します。この理論によれば、サンプルの複雑性、すなわち学習するのに必要な例の数は、仮説クラスのVC次元に依存して増加します。この関係は、プラクティショナーがモデルクラスや正則化戦略を選択して、表現力と一般化をバランスさせる際の指針となります。
実世界のアプリケーションでは、VC次元はサポートベクトルマシン(SVM)、決定木、ニューラルネットワークなどのアルゴリズムの設計および評価を知らせます。たとえば、SVMはVC理論と密接に関連しており、そのマージン最大化の原則は分類器の効果的なVC次元を制御する方法として解釈できるため、一般化性能を向上させることができます。同様に、決定木のプルーニング手法は、VC次元を減少させ、過学習を軽減するための手法として見ることができます。
複雑なモデル、たとえば深層ニューラルネットワークの正確なVC次元を計算することはしばしば困難ではありますが、この概念は研究と実践の進展を促す影響を及ぼします。それは、正則化手法、モデル選択基準、および学習性能に関する理論的制約の発展の基盤となります。VC次元の持続的な関連性は、機械学習の理論およびその実用的応用における研究を推進する組織である人工知能の進歩協会やコンピュータ機械協会によって反映されています。
VC次元の限界と批評
バプニク–チェルヴォネンキス(VC)次元は、データポイントをシャタリングする能力に関して、関数の集合(仮説クラス)のキャパシティまたは複雑さを測定する基礎的な概念です。その理論的な意味にもかかわらず、VC次元にはいくつかの著名な限界があり、機械学習や統計のコミュニティ内でさまざまな批評の対象となっています。
VC次元の主な限界の一つは、最悪のシナリオに焦点を当てている点です。VC次元は、仮説クラスによってシャタリング可能な最大の点の集合を定量化しますが、これは実際の環境における学習アルゴリズムの典型的または平均的な性能を反映しているわけではありません。そのため、VC次元は、アドバーサリや最悪のケースからはほど遠い実世界のデータで成功するために必要な真の複雑さを過大評価する可能性があります。この乖離は、サンプルの複雑性や一般化誤差に対する過度に悲観的な制限に繋がる可能性があります。
また、現代の機械学習モデル、特に深層ニューラルネットワークに対するVC次元の適用性についての批評もあります。VC次元は、線形分類器や決定木などの単純な仮説クラスには明確に定義されていますが、高度にパラメータ化されたモデルに対しては、計算や意味のある解釈が困難になります。多くの場合、深層ネットワークは非常に高い、または無限のVC次元を持っていても、実際には良好に一般化することがあります。この現象は「一般化パラドックス」と呼ばれ、VC次元は現代の機械学習システムにおける一般化を支配する要因を完全には捉えていないことを示唆しています。
さらに、VC次元は本質的に組み合わせ的な尺度であり、データ分布の幾何学や構造を無視します。マージンに基づく特性、正則化、または一般化に大きく影響を与える他のアルゴリズム的手法を考慮していません。ラデマヒアの複雑性やカバリング数などの代替的な複雑さの尺度は、データ依存性や幾何学的側面を組み込むことによって、いくつかのこれらの欠点に対処するために提案されてきました。
最後に、VC次元は、データポイントが独立かつ同一分布である(i.i.d.)と仮定する点に依存しています。この仮定は、多くの実世界のアプリケーション、たとえば時系列分析や構造化予測タスクでは成り立たない場合があります。これにより、特定の分野におけるVCベースの理論の直接的な適用性が制限されます。
これらの限界にもかかわらず、VC次元は学習理論の礎であり、学習可能性の基本的制約に関する貴重な洞察を提供します。人工知能の進歩協会や数学統計所などの組織による継続的な研究がVCフレームワークを拡張し、近代の機械学習における経験的観察に理論的保証をより良く調和させることを目指しています。
VC理論の将来の方向性と未解決問題
バプニク–チェルヴォネンキス(VC)次元は、統計的学習理論の礎であり、仮説クラスの容量と有限サンプルから一般化する能力を厳密に測定します。その基礎的な役割にもかかわらず、VC理論におけるいくつかの将来の方向性と未解決の問題が研究を進展させ続けています。これらは、理論的な課題と現代の機械学習における実践的な要求を反映しています。
一つの顕著な方向性は、VC理論をより複雑で構造化されたデータ領域に拡張することです。従来のVC次元の分析は、バイナリ分類や単純な仮説空間に適していましたが、現代のアプリケーションでは、多クラス、構造化出力、または複雑な依存関係を持つデータが多く含まれています。深層ニューラルネットワーク、リカレントアーキテクチャ、その他の高度なモデルの複雑さを捉えるVC次元の一般化概念の開発は、未解決の課題です。これには、これらのモデルの効果的なキャパシティと、それが経験的なパフォーマンスや一般化能力とどのように関連するかを理解することが含まれます。
もう一つの活発な研究分野は、VC次元の計算的側面です。VC次元は理論的保証を提供しますが、任意の仮説クラスに対するVC次元を計算したり近似したりすることはしばしば困難です。特に大規模または高次元モデルに対して、VC次元を推定するための効率的なアルゴリズムが強く求められています。これは、モデル選択、正則化、モデルの複雑性を適応的に制御できる学習アルゴリズムの設計に影響を与えます。
VC次元とラデマヒアの複雑性、カバリング数、アルゴリズムの安定性などの他の複雑さの尺度との関係は、探求の肥沃な土壌を提供します。機械学習モデルがますます洗練される中、これらの異なる尺度がどのように相互作用し、どれが実際の一般化の予測に最も役立つかを理解することは、大きな未解決の問題です。これは、古典的なVC理論が観察される一般化現象を完全には説明できない場合が多い、過パラメトリックモデルの文脈では特に重要です。
さらに、データプライバシーや公正性の懸念の出現は、VC理論に新たな次元をもたらします。研究者たちは、差分プライバシーや公正性要件などの制約がVC次元に、さらに仮説クラスの学習可能性にどのように影響を与えるかを調査しています。倫理的および法律的考慮とのVC理論の交差点は、機械学習システムがますますセンシティブなドメインで展開されるため、重要性が増していくことでしょう。
最後に、量子コンピューティングの進展と機械学習への潜在的な応用は、量子仮説空間におけるVC次元についての疑問を提起します。量子リソースが学習アルゴリズムのキャパシティと一般化にどのように影響を与えるかを理解することは、理論探求の新たな分野となっています。
この分野が進化する中で、人工知能の進歩協会や数学統計所などの組織は、VC理論の進展に対する研究と普及を促進し続け、基本的な問いが機械学習研究の最前線にとどまることを保証しています。
出典・参考文献