Demistyfikacja Wymiaru Vapnika–Czernowicza: Klucz do Zrozumienia Złożoności Modelu i Generalizacji w Uczeniu Maszynowym. Odkryj Wpływ Wymiaru VC na Granice Możliwości Uczenia Algorytmów.
- Wprowadzenie do Wymiaru Vapnika–Czernowicza
- Historyczne Pochodzenie i Teoretyczne Fundamenty
- Formalna Definicja i Ramy Matematyczne
- Wymiar VC w Klasyfikacji Binarniej
- Rozdrabnianie, Funkcje Wzrostu i Ich Znaczenie
- Wymiar VC a Zdolność Modelu: Implikacje Praktyczne
- Powiązania z Przeuczeniem i Granicami Generalizacji
- Wymiar VC w Rzeczywistych Algorytmach Uczenia Maszynowego
- Ograniczenia i Krytyka Wymiaru VC
- Przyszłe Kierunki i Otwarte Problemy w Teorii VC
- Źródła i Odniesienia
Wprowadzenie do Wymiaru Vapnika–Czernowicza
Wymiar Vapnika–Czernowicza (wymiar VC) to fundamentalna koncepcja w teorii uczenia statystycznego, wprowadzona przez Władimira Vapnika i Aleksieja Czernowicza na początku lat 70. XX wieku. Zapewnia rygorystyczne ramy matematyczne do kwantyfikacji zdolności lub złożoności zbioru funkcji (klasy hipotez) w odniesieniu do jej możliwości klasyfikacji punktów danych. Wymiar VC definiowany jest jako największa liczba punktów, które mogą być rozdrabniane (tj. poprawnie klasyfikowane na wszystkie możliwe sposoby) przez klasę hipotez. Koncepcja ta ma kluczowe znaczenie dla zrozumienia zdolności generalizacji algorytmów uczących się, ponieważ łączy ekspresyjność modelu z ryzykiem przeuczenia.
Mówiąc bardziej formalnie, jeśli klasa hipotez może rozdrabniać zbiór n punktów, ale nie może rozdrabniać żadnego zbioru n+1 punktów, to jej wymiar VC wynosi n. Na przykład klasa klasyfikatorów liniowych w przestrzeni dwuwymiarowej ma wymiar VC równy 3, co oznacza, że może rozdrabniać dowolny zbiór trzech punktów, ale nie wszystkie zbiory czterech punktów. Wymiar VC służy więc jako miara bogactwa klasy hipotez, niezależnie od konkretnego rozkładu danych.
Znaczenie wymiaru VC polega na jego roli w zapewnieniu teoretycznych gwarancji dla algorytmów uczenia maszynowego. Jest kluczowym elementem w derivacji granic błędu generalizacji, który jest różnicą między błędem w danych treningowych a oczekiwanym błędem w danych nieznanych. Znana nierówność VC, na przykład, łączy wymiar VC z prawdopodobieństwem, że ryzyko empiryczne (błąd treningowy) odbiega od prawdziwego ryzyka (błąd generalizacji). Ta relacja stanowi podstawę zasady minimalizacji ryzyka strukturalnego, która jest fundamentem nowoczesnej teorii uczenia statystycznego, dążąc do zrównoważenia złożoności modelu i błędu treningowego w celu osiągnięcia optymalnej generalizacji.
Koncepcja wymiaru VC została szeroko przyjęta w analizie różnych algorytmów uczenia, w tym maszyn wektorów nośnych, sieci neuronowych i drzew decyzyjnych. Jest również podstawowa w rozwoju ramy uczenia prawdopodobnie w przybliżeniu poprawnego (PAC), która formalizuje warunki, w jakich można oczekiwać, że algorytm uczenia będzie działał dobrze. Teoretyczne podstawy zapewnione przez wymiar VC miały kluczowe znaczenie dla postępu w dziedzinie uczenia maszynowego i są dostrzegane przez wiodące instytucje badawcze, takie jak Instytut Badań Zaawansowanych oraz Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji.
Historyczne Pochodzenie i Teoretyczne Fundamenty
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, wprowadzoną na początku lat 70. XX wieku przez Władimira Vapnika i Aleksieja Czernowicza. Ich pionierska praca wyłoniła się z Instytutu Nauk Kontroli Rosyjskiej Akademii Nauk, gdzie starali się sformalizować zasady leżące u podstaw rozpoznawania wzorców i uczenia maszynowego. Wymiar VC zapewnia rygorystyczne ramy matematyczne do kwantyfikacji zdolności zbioru funkcji (klasy hipotez) do dopasowywania danych, co jest kluczowe dla zrozumienia zdolności generalizacji algorytmów uczenia się.
W swojej istocie, wymiar VC mierzy największą liczbę punktów, które mogą być rozdrabniane (tj. poprawnie klasyfikowane na wszystkie możliwe sposoby) przez klasę hipotez. Jeśli klasa funkcji może rozdrabniać zbiór o wielkości d, ale nie d+1, to jej wymiar VC wynosi d. Ta koncepcja pozwala badaczom analizować kompromis między złożonością modelu a ryzykiem przeuczenia, co jest centralnym zmartwieniem w uczeniu maszynowym. Wprowadzenie wymiaru VC stanowiło znaczący postęp w stosunku do wcześniejszych, mniej formalnych podejść do teorii uczenia, zapewniając most między empirycznymi wynikami a teoretycznymi gwarancjami.
Teoretyczne podstawy wymiaru VC są ściśle związane z rozwojem ramy uczenia prawdopodobnie w przybliżeniu poprawnego (PAC), która formalizuje warunki, w jakich można oczekiwać, że algorytm uczenia będzie działał dobrze na danych nieznanych. Wymiar VC jest kluczowym parametrem w twierdzeniach, które ograniczają błąd generalizacji klasyfikatorów, ustalając, że skończony wymiar VC jest konieczny dla nauczalności w sensie PAC. Ta intuicja miała głęboki wpływ na projektowanie i analizę algorytmów w dziedzinach ranging from computer vision to natural language processing.
Prace Vapnika i Czernowicza położyły podwaliny pod rozwój maszyn wektorów nośnych i innych metod bazujących na kernelach, które opierają się na zasadach kontroli zdolności i minimalizacji ryzyka strukturalnego. Ich wkład został doceniony przez wiodące organizacje naukowe, a wymiar VC pozostaje centralnym tematem w programie nauczania zaawansowanych kursów uczenia maszynowego i statystyki na całym świecie. Amerykańskie Towarzystwo Matematyczne oraz Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji to niektóre z organizacji, które podkreśliły znaczenie tych teoretycznych osiągnięć w swoich publikacjach i konferencjach.
Formalna Definicja i Ramy Matematyczne
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, zapewniającą rygorystyczną miarę zdolności lub złożoności zbioru funkcji (klasy hipotez) w odniesieniu do jej możliwości klasyfikacji punktów danych. Formalnie, wymiar VC definiowany jest dla klasy funkcji wskaźnikowych (lub zbiorów) jako największa liczba punktów, które mogą być rozdrabniane przez tę klasę. „Rozdrabniać” zbiór punktów oznacza, że dla każdego możliwego etykietowania tych punktów istnieje funkcja w klasie, która poprawnie przypisuje te etykiety.
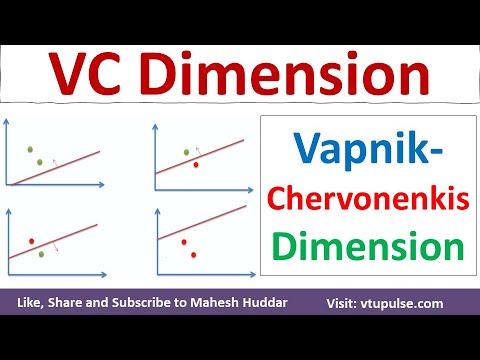
Niech H będzie klasą hipotez funkcji o wartościach binarnych mapujących z przestrzeni wejściowej X na {0,1}. Zbiór punktów S = {x₁, x₂, …, xₙ} jest określany jako rozdrabniany przez H, jeśli dla każdego możliwego podzbioru A z S istnieje funkcja h ∈ H, taka że h(x) = 1</i, jeśli i tylko jeśli x ∈ A. Wymiar VC klasy H, oznaczany jako VC(H), jest maksymalną licznością n, dla której istnieje zbiór n punktów w X, rozdrabniany przez H. Jeśli można rozdrabniać dowolnie duże skończone zbiory, wymiar VC jest nieskończony.
Matematycznie, wymiar VC zapewnia most między ekspresyjnością klasy hipotez a jej zdolnością do generalizacji. Wyższy wymiar VC wskazuje na bardziej ekspresywną klasę, zdolną do dopasowywania bardziej złożonych wzorców, ale również na większe ryzyko przeuczenia. Odwrotnie, niższy wymiar VC sugeruje ograniczoną ekspresyjność i potencjalnie lepszą generalizację, ale być może kosztem niedouczenia. Wymiar VC jest kluczowy dla derivacji granic generalizacji, takich jak te sformalizowane w fundamentalnych twierdzeniach teorii uczenia statystycznego, które łączą wymiar VC z złożonością próby wymaganą do nauki z daną dokładnością i pewnością.
Koncepcja ta została wprowadzona przez Władimira Vapnika i Aleksieja Czernowicza w latach 70. XX wieku i stanowi podstawę teoretycznej analizy algorytmów uczenia, w tym maszyn wektorów nośnych oraz ram empirycznej minimalizacji ryzyka. Wymiar VC jest powszechnie rozpoznawany i stosowany w dziedzinie uczenia maszynowego, a szczegółowo omawiają go organizacje takie jak Instytut Statystyki Matematycznej oraz Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji, które są wiodącymi autorytetami w badaniach nad statystyką i sztuczną inteligencją.
Wymiar VC w Klasyfikacji Binarniej
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, szczególnie istotną w analizie modeli klasyfikacji binarnej. Wprowadzony przez Władimira Vapnika i Aleksieja Czernowicza na początku lat 70. XX wieku, wymiar VC kwantyfikuje zdolność lub złożoność zbioru funkcji (klasy hipotez) poprzez pomiar jej zdolności do rozdrabniania skończonych zbiorów punktów danych. W kontekście klasyfikacji binarnej „rozdrabnianie” odnosi się do zdolności klasyfikatora do poprawnego etykietowania wszystkich możliwych przyporządkowań etykiet binarnych (0 lub 1) do danego zbioru punktów.
Formalnie, wymiar VC klasy hipotez to największa liczba punktów, które mogą być rozdrabniane przez tę klasę. Na przykład rozważmy klasę klasyfikatorów liniowych (perceptronów) w przestrzeni dwuwymiarowej. Ta klasa może rozdrabniać dowolny zbiór trzech punktów w ogólnej pozycji, ale nie wszystkie zbiory czterech punktów. Dlatego wymiar VC klasyfikatorów liniowych w dwóch wymiarach wynosi trzy. Wymiar VC dostarcza miary ekspresyjności modelu: wyższy wymiar VC wskazuje na bardziej elastyczny model, który może dopasować bardziej złożone wzorce, ale także zwiększa ryzyko przeuczenia.
W klasyfikacji binarnej wymiar VC odgrywa kluczową rolę w zrozumieniu kompromisu między złożonością modelu a generalizacją. Zgodnie z teorią, jeśli wymiar VC jest zbyt wysoki w stosunku do liczby próbek treningowych, model może idealnie dopasować dane treningowe, ale nie zdoła generalizować na dane nieznane. Odwrotnie, model o niskim wymiarze VC może być zbyt prosty, nie uchwycając istotnych wzorców w danych. W związku z tym wymiar VC dostarcza teoretycznych gwarancji na błąd generalizacji, sformalizowanych w nierówności VC oraz powiązanych granicach.
Koncepcja wymiaru VC jest kluczowa dla rozwoju algorytmów uczenia i analizy ich wydajności. Stanowi podstawę ramy uczenia prawdopodobnie w przybliżeniu poprawnego (PAC), która charakteryzuje warunki, w jakich algorytm uczenia może osiągnąć niski błąd generalizacji z dużym prawdopodobieństwem. Wymiar VC jest również używany w projektowaniu i analizie maszyn wektorów nośnych (SVM), powszechnie stosowanej klasy klasyfikatorów binarnych, a także w badaniu sieci neuronowych i innych modeli uczenia maszynowego.
Znaczenie wymiaru VC w klasyfikacji binarnej zostało uznane przez wiodące instytucje badawcze i organizacje w dziedzinie sztucznej inteligencji i uczenia maszynowego, takie jak Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji oraz Stowarzyszenie Maszyn Obliczeniowych. Te organizacje wspierają badania i upowszechnianie podstawowych koncepcji, takich jak wymiar VC, które wciąż kształtują teoretyczne podstawy i praktyczne zastosowania uczenia maszynowego.
Rozdrabnianie, Funkcje Wzrostu i Ich Znaczenie
Koncepcje rozdrabniania i funkcji wzrostu są kluczowe dla zrozumienia wymiaru Vapnika–Czernowicza (VC), podstawowej miary w teorii uczenia statystycznego. Wymiar VC, wprowadzony przez Władimira Vapnika i Aleksieja Czernowicza, kwantyfikuje zdolność zbioru funkcji (klasy hipotez) do dopasowywania danych i jest kluczowy dla analizy zdolności generalizacji algorytmów uczących się.
Rozdrabnianie odnosi się do zdolności klasy hipotez do doskonałego klasyfikowania wszystkich możliwych etykietowań skończonego zbioru punktów. Formalnie, zbiór punktów nazywamy rozdrabnianym przez klasę hipotez, jeśli dla każdego możliwego przyporządkowania etykiet binarnych do punktów istnieje funkcja w klasie, która poprawnie oddziela punkty zgodnie z tymi etykietami. Na przykład w przypadku klasyfikatorów liniowych w dwóch wymiarach, dowolny zbiór trzech niekolinearnych punktów może być rozdrabniany, ale nie wszystkie zbiory czterech punktów mogą być.
Funkcja wzrostu, znana również jako współczynnik rozdrabniania, mierzy maksymalną liczbę różnych etykietowań (dichotomii), które klasa hipotez może zrealizować dla dowolnego zbioru n punktów. Jeśli klasa hipotez może rozdrabniać każdy zbiór n punktów, funkcja wzrostu wynosi 2n. Jednak w miarę wzrostu n większość klas hipotez osiąga moment, w którym nie mogą już rozdrabniać wszystkich możliwych etykietowań, a funkcja wzrostu rośnie wolniej. Wymiar VC definiowany jest jako największa liczba całkowita d, dla której funkcja wzrostu wynosi 2d; innymi słowy, jest to rozmiar największego zbioru, który może być rozdrabniany przez klasę hipotez.
Te koncepcje są istotne, ponieważ zapewniają rygorystyczny sposób analizy złożoności i ekspresyjnej mocy modeli uczeń. Wyższy wymiar VC wskazuje na bardziej ekspresyjny model, zdolny do dopasowywania bardziej złożonych wzorców, ale również na większe ryzyko przeuczenia. Odwrotnie, niski wymiar VC sugeruje ograniczoną zdolność, co może prowadzić do niedouczenia. Wymiar VC jest bezpośrednio powiązany z granicami generalizacji: pomaga określić, ile danych treningowych potrzebnych jest do zapewnienia, że wydajność modelu na danych nieznanych będzie bliska wydajności na zbiorze treningowym. Ta relacja jest sformalizowana w twierdzeniach, takich jak fundamentalne twierdzenie teorii uczenia statystycznego, które stanowi podstawę znacznej części nowoczesnej teorii uczenia maszynowego.
Badanie rozdrabniania i funkcji wzrostu oraz ich powiązań z wymiarem VC jest podstawowe w pracy organizacji takich jak Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji oraz Instytut Statystyki Matematycznej, które promują badania i upowszechnianie postępów w teorii uczenia statystycznego oraz jej zastosowaniach.
Wymiar VC a Zdolność Modelu: Implikacje Praktyczne
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, zapewniającą rygorystyczną miarę zdolności lub złożoności zbioru funkcji (klasy hipotez), które model uczenia maszynowego może zaimplementować. W praktycznych aspektach wymiar VC kwantyfikuje największą liczbę punktów, które można rozdrabniać (tj. poprawnie klasyfikować na wszystkie możliwe sposoby) przez model. Miara ta jest kluczowa dla zrozumienia kompromisu między zdolnością modelu do dopasowywania danych treningowych a jego zdolnością do generalizacji na dane nieznane.
Wyższy wymiar VC wskazuje na bardziej ekspresywną klasę modelu, zdolną do reprezentowania bardziej złożonych wzorców. Na przykład klasyfikator liniowy w przestrzeni dwuwymiarowej ma wymiar VC równy 3, co oznacza, że może rozdrabniać dowolny zbiór trzech punktów, ale nie wszystkie zbiory czterech. W przeciwieństwie do tego bardziej złożone modele, takie jak sieci neuronowe z wielu parametrami, mogą mieć znacznie wyższe wymiary VC, co odzwierciedla ich większą zdolność do dopasowywania różnorodnych zbiorów danych.
Implikacje praktyczne wymiaru VC są najbardziej widoczne w kontekście przeuczenia i niedouczenia. Jeśli wymiar VC modelu jest znacznie większy niż liczba próbek treningowych, model może przeuczyć się—zapamiętując dane treningowe zamiast ucząc się ogólnych wzorców. Odwrotnie, jeżeli wymiar VC jest zbyt niski, model może być niedouczony, nie uchwyciwszy istotnej struktury danych. Dlatego wybór modelu z odpowiednim wymiarem VC w stosunku do rozmiaru zbioru danych jest kluczowy dla osiągnięcia dobrej wydajności generalizacji.
Wymiar VC podstawą teoretycznych gwarancji w teorii uczenia, takich jak ramy PAC (Prawdopodobnie Prawie Poprawne). Zapewnia granice dotyczące liczby prób wymaganych do zapewnienia, że ryzyko empiryczne (błąd w zbiorze treningowym) jest bliskie prawdziwemu ryzyku (oczekiwany błąd w nowych danych). Wyniki te prowadzą praktyków do szacowania złożoności próby potrzebnej do niezawodnego uczenia, zwłaszcza w aplikacjach wymagających dużej niezawodności, takich jak diagnoza medyczna czy systemy autonomiczne.
W praktyce, choć dokładny wymiar VC jest często trudny do obliczenia dla złożonych modeli, jego rola koncepcyjna informuje projektowanie i wybór algorytmów. Techniki regularizacji, kryteria wyboru modeli i strategie walidacji krzyżowej są wszystkie wpływane przez podstawowe zasady kontroli zdolności opisywane przez wymiar VC. Koncepcję tę wprowadził Władimir Vapnik oraz Aleksiej Czernowicz, których prace położyły podwaliny pod nowoczesną teorię uczenia statystycznego i wciąż wpływają na badania oraz aplikacje w uczeniu maszynowym (Instytut Statystyki Matematycznej).
Powiązania z Przeuczeniem i Granicami Generalizacji
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, która bezpośrednio wpływa na nasze zrozumienie przeuczenia i generalizacji w modelach uczenia maszynowego. Wymiar VC kwantyfikuje zdolność lub złożoność zbioru funkcji (klasy hipotez) poprzez pomiar największego zbioru punktów, które mogą być rozdrabniane—tj. poprawnie klasyfikowane na wszystkie możliwe sposoby—przez funkcje w klasie. Ta miara jest kluczowa dla analizy tego, jak dobrze model wytrenowany na skończonym zbiorze danych będzie działał na danych nieznanych, właściwości zwanej generalizacją.
Przeuczenie występuje, gdy model uczy się nie tylko podstawowych wzorców, ale także szumów w danych treningowych, co skutkuje słabymi wynikami na nowych, nieznanych danych. Wymiar VC dostarcza teoretycznych ram do zrozumienia i łagodzenia przeuczenia. Jeśli wymiar VC klasy hipotez jest znacznie większy niż liczba próbek treningowych, model ma wystarczającą zdolność do dopasowania losowego szumu, co zwiększa ryzyko przeuczenia. Odwrotnie, jeśli wymiar VC jest zbyt niski, model może być niedouczony, nie uchwyciwszy istotnej struktury danych.
Relacja między wymiarem VC a generalizacją jest sformalizowana przez granice generalizacji. Te granice, takie jak te wynikające z fundamentalnej pracy Władimira Vapnika i Aleksieja Czernowicza, stwierdzają, że z dużym prawdopodobieństwem różnica między ryzykiem empirycznym (błędem w zbiorze treningowym) a prawdziwym ryzykiem (oczekiwanym błędem w nowych danych) jest mała, jeśli liczba próbek treningowych jest wystarczająco duża w stosunku do wymiaru VC. Konkretnie, błąd generalizacji maleje w miarę wzrostu liczby próbek, pod warunkiem że wymiar VC pozostaje stały. Ta intuicja stanowi podstawę zasady, że bardziej złożone modele (o wyższym wymiarze VC) wymagają większej ilości danych, aby dobrze generalizować.
- Wymiar VC jest kluczowy dla teorii zbieżności jednorodnej, która zapewnia, że empiryczne średnie zbieżają do oczekiwanych wartości jednorodnie we wszystkich funkcjach w klasie hipotez. Właściwość ta jest niezbędna dla zapewnienia, że minimalizacja błędu w zbiorze treningowym prowadzi do niskiego błędu w danych nieznanych.
- Koncepcja ta jest również integralna dla rozwoju minimalizacji ryzyka strukturalnego, strategii, która równoważy złożoność modelu i błąd treningowy w celu osiągnięcia optymalnej generalizacji, jak to sformalizowano w teorii maszyn wektorów nośnych i innych algorytmów uczenia.
Znaczenie wymiaru VC w zrozumieniu przeuczenia i generalizacji zostało dostrzegnięte przez wiodące instytucje badawcze i jest podstawowe w programie nauczania teorii uczenia statystycznego, jak to określają organizacje takie jak Instytut Badań Zaawansowanych oraz Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji. Organizacje te przyczyniają się do ciągłego rozwoju i upowszechniania teoretycznych osiągnięć w uczeniu maszynowym.
Wymiar VC w Rzeczywistych Algorytmach Uczenia Maszynowego
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, providing a rigorous measure of the capacity or complexity of a set of functions (hypothesis class) that a machine learning algorithm can implement. W rzeczywistym uczeniu maszynowym wymiar VC odgrywa kluczową rolę w zrozumieniu zdolności generalizacji algorytmów—jak dobrze model wyuczony na skończonej próbce ma przewidywać na niewidzianych danych.
W praktycznych aspektach wymiar VC pomaga kwantyfikować kompromis między złożonością modelu a ryzykiem przeuczenia. Na przykład klasyfikator liniowy w przestrzeni dwuwymiarowej (taki jak perceptron) ma wymiar VC równy 3, co oznacza, że może rozdrabniać dowolny zbiór trzech punktów, ale nie wszystkie zbiory czterech. Bardziej złożone modele, takie jak sieci neuronowe, mogą mieć znacznie wyższe wymiary VC, co odzwierciedla ich zdolność do dopasowywania bardziej skomplikowanych wzorców w danych. Niemniej jednak, wyższy wymiar VC zwiększa również ryzyko przeuczenia, gdzie model uchwyca szum zamiast podstawowej struktury.
Wymiar VC jest szczególnie istotny w kontekście ramy uczenia prawdopodobnie w przybliżeniu poprawnego (PAC), która zapewnia teoretyczne gwarancje dotyczące liczby próbek treningowych niezbędnych do osiągnięcia pożądanego poziomu dokładności i pewności. Zgodnie z teorią złożoność próbki—liczba przykładów potrzebnych do uczenia—wzrasta wraz z wymiarem VC klasy hipotez. Ta relacja prowadzi praktyków do wyboru odpowiednich klas modeli i strategii regularizacji w celu zrównoważenia ekspresyjności i generalizacji.
W zastosowaniach w rzeczywistości wymiar VC informuje projektowanie i ocenę algorytmów, takich jak maszyny wektorów nośnych (SVM), drzewa decyzyjne i sieci neuronowe. Na przykład SVM są ściśle związane z teorią VC, jako że ich zasada maksymalizacji marginesu może być interpretowana jako sposób kontrolowania efektywnego wymiaru VC klasyfikatora, w ten sposób poprawiając wydajność generalizacji. Podobnie techniki przycinania w drzewach decyzyjnych mogą być postrzegane jako metody redukcji wymiaru VC i łagodzenia przeuczenia.
Chociaż dokładny wymiar VC złożonych modeli, takich jak głębokie sieci neuronowe, często jest trudny do obliczenia, koncepcja ta pozostaje wpływowa w prowadzeniu badań i praktyk. Stanowi podstawę rozwoju metod regularizacji, kryteriów wyboru modeli oraz teoretycznych granic wydajności uczenia. Trwała relewantność wymiaru VC odzwierciedla jego podstawową rolę w pracach organizacji takich jak Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji oraz Stowarzyszenie Maszyn Obliczeniowych, które promują badania w teorii uczenia maszynowego i jej praktycznych implikacjach.
Ograniczenia i Krytyka Wymiaru VC
Wymiar Vapnika–Czernowicza (VC) jest fundamentalną koncepcją w teorii uczenia statystycznego, providing a measure of the capacity or complexity of a set of functions (hypothesis class) w kontekście jego zdolności do rozdrabniania punktów danych. Pomimo swojej teoretycznej znaczenia, wymiar VC ma kilka wyraźnych ograniczeń i był przedmiotem różnych krytyków wśród społeczności uczenia maszynowego i statystycznych.
Jednym z głównych ograniczeń wymiaru VC jest jego skoncentrowanie na najgorszych scenariuszach. Wymiar VC kwantyfikuje największy zbiór punktów, które mogą być rozdrabniane przez klasę hipotez, ale nie zawsze odzwierciedla typowe lub średnie wyniki algorytmów uczenia maszynowego w praktycznych ustawieniach. W rezultacie wymiar VC może przeszacowywać prawdziwą złożoność wymaganą do udanej generalizacji w rzeczywistych danych, gdzie rozkłady są często dalekie od adwersarialnych lub najgorszego przypadku. To disconnect może prowadzić do zbyt pesymistycznych granic na złożoność próbkową i błąd generalizacji.
Inną krytyką dotyczy zastosowania wymiaru VC do nowoczesnych modeli uczenia maszynowego, szczególnie głębokich sieci neuronowych. Chociaż wymiar VC jest dobrze zdefiniowany dla prostych klas hipotez, takich jak klasyfikatory liniowe lub drzewa decyzyjne, staje się trudny do obliczenia lub nawet znacząco zinterpretowania dla wysoce parametryzowanych modeli. W wielu przypadkach głębokie sieci mogą mieć niezwykle wysokie lub nawet nieskończone wymiary VC, a mimo to generalizować dobrze w praktyce. To zjawisko, czasami określane jako „paradoks generalizacji”, sugeruje, że wymiar VC nie w pełni odzwierciedla czynniki regulujące generalizację w nowoczesnych systemach uczenia maszynowego.
Dodatkowo, wymiar VC jest inherentnie miarą kombinatoryczną, ignorującą geometrię i strukturę rozkładu danych. Nie uwzględnia właściwości opartej na marginesie, regularizacji ani innych technik algorytmicznych, które mogą znacząco wpływać na generalizację. Alternatywne miary złożoności, takie jak złożoność Rademachera czy liczby pokrywania, zostały zaproponowane w celu rozwiązania niektórych z tych niedociągnięć, uwzględniając aspekty zależne od danych lub geometryczne.
Na koniec, wymiar VC zakłada, że punkty danych są niezależne i identycznie rozdzielone (i.i.d.), co niekoniecznie ma miejsce w wielu rzeczywistych zastosowaniach, takich jak analiza szeregów czasowych czy zadania przewidywania strukturalnego. To dalej ogranicza bezpośrednią zastosowalność teorii opartej na VC w niektórych dziedzinach.
Pomimo tych ograniczeń wymiar VC pozostaje fundamentem teorii uczenia, dostarczając cennych wskazówek dotyczących fundamentalnych ograniczeń uczenia się. Ciągłe badania przez organizacje takie jak Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji i Instytut Statystyki Matematycznej nadal eksplorują rozszerzenia i alternatywy dla ramy VC, dążąc do lepszego dopasowania teoretycznych gwarancji do empirycznych obserwacji w nowoczesnym uczeniu maszynowym.
Przyszłe Kierunki i Otwarte Problemy w Teorii VC
Wymiar Vapnika–Czernowicza (VC) pozostaje fundamentem teorii uczenia statystycznego, zapewniając rygorystyczną miarę zdolności klas hipotez i ich możliwości generalizacji na podstawie skończonych próbek. Pomimo swojej fundamentalnej roli, kilka przyszłych kierunków oraz otwartych problemów wciąż napędza badania w teorii VC, odzwierciedlając zarówno wyzwania teoretyczne, jak i praktyczne wymagania w nowoczesnym uczeniu maszynowym.
Jednym z prominentnych kierunków jest rozszerzenie teorii VC na bardziej złożone i strukturalne domeny danych. Tradycyjna analiza wymiaru VC jest dobrze dostosowana do klasyfikacji binarnej i prostych przestrzeni hipotez, ale nowoczesne aplikacje często obejmują multi-klasowe, złożone wyjścia lub dane z zawiłymi zależnościami. Rozwój uogólnionych pojęć wymiaru VC, które mogą uchwycić złożoność głębokich sieci neuronowych, architektur rekurencyjnych i innych zaawansowanych modeli, pozostaje otwartym wyzwaniem. To obejmuje zrozumienie efektywnej zdolności tych modeli i ich powiązań z wydajnością empiryczną oraz zdolnością do generalizacji.
Innym aktywnym obszarem badań jest aspekt obliczeniowy wymiaru VC. Chociaż wymiar VC dostarcza teoretycznych gwarancji, obliczanie lub nawet przybliżanie wymiaru VC dla dowolnych klas hipotez jest często niewykonalne. Efektywne algorytmy do szacowania wymiaru VC, szczególnie dla modeli dużych lub o wysokiej wymiarowości, są bardzo poszukiwane. Ma to implikacje dla wyboru modelu, regularizacji oraz projektowania algorytmów uczenia, które mogą adaptacyjnie kontrolować złożoność modelu.
Relacja między wymiarem VC a innymi miarami złożoności, takimi jak złożoność Rademachera, liczby pokrywania i stabilność algorytmiczna, również stwarza żyzne pole do eksploracji. W miarę jak modele uczenia maszynowego stają się coraz bardziej wyrafinowane, zrozumienie, jak te różne miary współdziałają oraz które z nich są najbardziej predykcyjne dla generalizacji w praktyce, staje się kluczowym otwartym problemem. Jest to szczególnie istotne w kontekście modeli przeregulowanych, w których klasyczna teoria VC może не wyjaśniać w pełni obserwowanych zjawisk generalizacji.
Ponadto, pojawienie się zagadnień związanych z prywatnością danych i sprawiedliwością wprowadza nowe wymiary do teorii VC. Naukowcy badają, jak ograniczenia, takie jak prywatność różnicowa lub wymagania dotyczące sprawiedliwości, wpływają na wymiar VC i, w konsekwencji, na uczenie się klas hipotez pod tymi ograniczeniami. To połączenie teorii VC z etycznymi i prawnymi rozważaniami prawdopodobnie zyska na znaczeniu w miarę wprowadzania systemów uczenia maszynowego w wrażliwych dziedzinach.
Na koniec, ciągły rozwój komputerów kwantowych i ich potencjalne zastosowania w uczeniu maszynowym stawiają pytania dotyczące wymiaru VC w kwantowych przestrzeniach hipotez. Zrozumienie, jak zasoby kwantowe wpływają na zdolność i generalizację algorytmów uczenia się, jest nowym obszarem teoretycznych badań.
W miarę jak dziedzina ewoluuje, organizacje takie jak Stowarzyszenie na rzecz Postępu Sztucznej Inteligencji oraz Instytut Statystyki Matematycznej nadal wspierają badania i upowszechnianie nowoczesnych osiągnięć w teorii VC, zapewniając, że fundamentalne pytania pozostają w centrum uwagi badań nad uczeniem maszynowym.
Źródła i Odniesienia
- Instytut Badań Zaawansowanych
- Amerykańskie Towarzystwo Matematyczne
- Stowarzyszenie Maszyn Obliczeniowych