Desmistificando a Dimensão Vapnik–Chervonenkis: A Chave para Entender a Complexidade do Modelo e Generalização em Aprendizado de Máquina. Descubra Como a Dimensão VC Forma os Limites do que os Algoritmos Podem Aprender.
- Introdução à Dimensão Vapnik–Chervonenkis
- Origens Históricas e Fundamentos Teóricos
- Definição Formal e Estrutura Matemática
- Dimensão VC na Classificação Binária
- Shattering, Funções de Crescimento e Sua Importância
- Dimensão VC e Capacidade do Modelo: Implicações Práticas
- Conexões com Overfitting e Limites de Generalização
- Dimensão VC em Algoritmos de Aprendizado de Máquina do Mundo Real
- Limitações e Críticas à Dimensão VC
- Direções Futuras e Problemas Abertos na Teoria VC
- Fontes & Referências
Introdução à Dimensão Vapnik–Chervonenkis
A dimensão Vapnik–Chervonenkis (dimensão VC) é um conceito fundamental na teoria do aprendizado estatístico, introduzido por Vladimir Vapnik e Alexey Chervonenkis no início da década de 1970. Ela fornece uma estrutura matemática rigorosa para quantificar a capacidade ou complexidade de um conjunto de funções (classe de hipóteses) em termos da sua capacidade de classificar pontos de dados. A dimensão VC é definida como o maior número de pontos que podem ser “shattered” (ou seja, corretamente classificados de todas as maneiras possíveis) pela classe de hipóteses. Este conceito é central para entender a capacidade de generalização dos algoritmos de aprendizado, pois conecta a expressividade de um modelo ao seu risco de overfitting.
Em termos mais formais, se uma classe de hipóteses pode “shatter” um conjunto de n pontos, mas não pode “shatter” nenhum conjunto de n+1 pontos, então sua dimensão VC é n. Por exemplo, a classe de classificadores lineares em um espaço bidimensional tem uma dimensão VC de 3, o que significa que ela pode “shatter” qualquer conjunto de três pontos, mas não todos os conjuntos de quatro pontos. A dimensão VC, portanto, serve como uma medida da riqueza de uma classe de hipóteses, independente da distribuição de dados específica.
A importância da dimensão VC reside em seu papel em fornecer garantias teóricas para algoritmos de aprendizado de máquina. É um componente chave na derivação de limites sobre o erro de generalização, que é a diferença entre o erro nos dados de treinamento e o erro esperado em dados não vistos. A célebre desigualdade VC, por exemplo, relaciona a dimensão VC à probabilidade de que o risco empírico (erro de treinamento) se desvie do risco verdadeiro (erro de generalização). Esta relação fundamenta o princípio da minimização de risco estrutural, um pilar da teoria moderna do aprendizado estatístico, que busca equilibrar a complexidade do modelo e o erro de treinamento para alcançar uma generalização ótima.
O conceito de dimensão VC foi amplamente adotado na análise de diversos algoritmos de aprendizado, incluindo máquinas de vetor de suporte, redes neurais e árvores de decisão. É também fundamental no desenvolvimento do quadro de aprendizado Provavelmente Aproximadamente Correto (PAC), que formaliza as condições sob as quais um algoritmo de aprendizado pode ser esperado para ter um bom desempenho. Os fundamentos teóricos fornecidos pela dimensão VC foram instrumentais no avanço do campo do aprendizado de máquina e são reconhecidos por instituições de pesquisa de destaque, como o Instituto para Estudos Avançados e a Associação para o Avanço da Inteligência Artificial.
Origens Históricas e Fundamentos Teóricos
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, introduzido no início da década de 1970 por Vladimir Vapnik e Alexey Chervonenkis. Seu trabalho pioneiro surgiu do Instituto de Ciências de Controle da Academia Russa de Ciências, onde eles buscaram formalizar os princípios subjacentes ao reconhecimento de padrões e aprendizado de máquina. A dimensão VC fornece uma estrutura matemática rigorosa para quantificar a capacidade de um conjunto de funções (classe de hipóteses) para ajustar dados, o que é crucial para entender a capacidade de generalização dos algoritmos de aprendizado.
Em seu núcleo, a dimensão VC mede o maior número de pontos que podem ser “shattered” (ou seja, corretamente classificados de todas as maneiras possíveis) por uma classe de hipóteses. Se uma classe de funções pode “shatter” um conjunto de tamanho d, mas não d+1, sua dimensão VC é d. Este conceito permite que os pesquisadores analisem a relação entre a complexidade do modelo e o risco de overfitting, uma preocupação central no aprendizado de máquina. A introdução da dimensão VC marcou um avanço significativo em relação a abordagens anteriores, menos formais, para a teoria do aprendizado, fornecendo uma ponte entre o desempenho empírico e as garantias teóricas.
Os fundamentos teóricos da dimensão VC estão estreitamente ligados ao desenvolvimento do quadro de aprendizado Provavelmente Aproximadamente Correto (PAC), que formaliza as condições sob as quais um algoritmo de aprendizado pode ser esperado para ter um bom desempenho em dados não vistos. A dimensão VC serve como um parâmetro chave em teoremas que limitam o erro de generalização dos classificadores, estabelecendo que uma dimensão VC finita é necessária para a aprendibilidade no sentido PAC. Este entendimento teve um impacto profundo no design e análise de algoritmos em campos que vão desde a visão computacional até o processamento de linguagem natural.
O trabalho de Vapnik e Chervonenkis lançou as bases para o desenvolvimento de máquinas de vetor de suporte e outros métodos baseados em kernel, que dependem dos princípios de controle da capacidade e minimização do risco estrutural. Contribuições deles foram reconhecidas por organizações científicas de destaque, e a dimensão VC continua sendo um assunto central no currículo de cursos avançados de aprendizado de máquina e estatísticas em todo o mundo. A Sociedade Americana de Matemática e a Associação para o Avanço da Inteligência Artificial estão entre as organizações que destacaram a importância desses avanços teóricos em suas publicações e conferências.
Definição Formal e Estrutura Matemática
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, fornecendo uma medida rigorosa da capacidade ou complexidade de um conjunto de funções (classe de hipóteses) em termos de sua capacidade de classificar pontos de dados. Formalmente, a dimensão VC é definida para uma classe de funções indicadoras (ou conjuntos) como o maior número de pontos que podem ser “shattered” pela classe. “Shatter” um conjunto de pontos significa que, para cada rotulagem possível desses pontos, existe uma função na classe que atribui corretamente esses rótulos.
Seja H uma classe de hipóteses de funções de valor binário que mapeiam de um espaço de entrada X para {0,1}. Um conjunto de pontos S = {x₁, x₂, …, xₙ} é dito ser “shattered” por H se, para cada subconjunto possível A de S, existe uma função h ∈ H tal que h(x) = 1 se e somente se x ∈ A. A dimensão VC de H, denotada VC(H), é a cardinalidade máxima n tal que existe um conjunto de n pontos em X que é “shattered” por H. Se conjuntos finitos arbitrariamente grandes podem ser “shattered”, a dimensão VC é infinita.
Matematicamente, a dimensão VC fornece uma ponte entre a expressividade de uma classe de hipóteses e sua capacidade de generalização. Uma maior dimensão VC indica uma classe mais expressiva, capaz de se ajustar a padrões mais complexos, mas também em maior risco de overfitting. Por outro lado, uma menor dimensão VC sugere expressividade limitada e potencialmente melhor generalização, mas possivelmente à custa de underfitting. A dimensão VC é central para a derivação de limites de generalização, como aqueles formalizados nos teoremas fundamentais da teoria do aprendizado estatístico, que relacionam a dimensão VC à complexidade de amostra necessária para aprender com uma dada precisão e confiança.
O conceito foi introduzido por Vladimir Vapnik e Alexey Chervonenkis na década de 1970, e fundamenta a análise teórica de algoritmos de aprendizado, incluindo máquinas de vetor de suporte e estruturas de minimização de risco empírico. A dimensão VC é amplamente reconhecida e utilizada no campo do aprendizado de máquina e é discutida em detalhes por organizações como o Instituto de Estatística Matemática e a Associação para o Avanço da Inteligência Artificial, ambas autoridades de destaque em pesquisa em estatística e inteligência artificial, respectivamente.
Dimensão VC na Classificação Binária
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, particularmente relevante para a análise de modelos de classificação binária. Introduzida por Vladimir Vapnik e Alexey Chervonenkis no início da década de 1970, a dimensão VC quantifica a capacidade ou complexidade de um conjunto de funções (classe de hipóteses) medindo sua capacidade de “shatter” conjuntos finitos de pontos de dados. No contexto da classificação binária, “shattering” refere-se à capacidade de um classificador de rotular corretamente todas as atribuições possíveis de rótulos binários (0 ou 1) para um determinado conjunto de pontos.
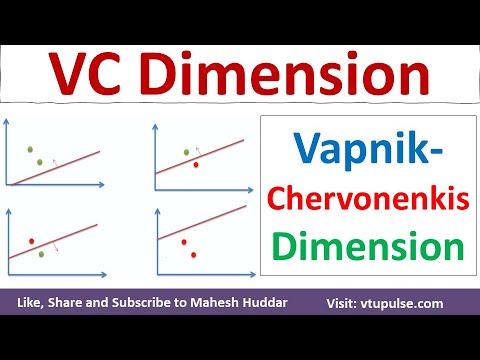
Formalmente, a dimensão VC de uma classe de hipóteses é o maior número de pontos que podem ser “shattered” por essa classe. Por exemplo, considere a classe de classificadores lineares (perceptrons) em um espaço bidimensional. Esta classe pode “shatter” qualquer conjunto de três pontos em posição geral, mas não todos os conjuntos de quatro pontos. Portanto, a dimensão VC dos classificadores lineares em duas dimensões é três. A dimensão VC fornece uma medida da expressividade de um modelo: uma maior dimensão VC indica um modelo mais flexível que pode se ajustar a padrões mais complexos, mas também aumenta o risco de overfitting.
Na classificação binária, a dimensão VC desempenha um papel crucial na compreensão da relação entre a complexidade do modelo e a generalização. Segundo a teoria, se a dimensão VC for muito alta em relação ao número de amostras de treinamento, o modelo pode se ajustar perfeitamente aos dados de treinamento, mas falhar em generalizar para novos dados não vistos. Por outro lado, um modelo com uma baixa dimensão VC pode sofrer underfitting, falhando em capturar padrões importantes nos dados. Assim, a dimensão VC fornece garantias teóricas sobre o erro de generalização, conforme formalizado na desigualdade VC e limites relacionados.
O conceito de dimensão VC é central para o desenvolvimento de algoritmos de aprendizado e análise de seu desempenho. Ele fundamenta o quadro de aprendizado Provavelmente Aproximadamente Correto (PAC), que caracteriza as condições sob as quais um algoritmo de aprendizado pode alcançar baixo erro de generalização com alta probabilidade. A dimensão VC também é utilizada no design e análise de máquinas de vetor de suporte (SVMs), uma classe amplamente utilizada de classificadores binários, bem como no estudo de redes neurais e outros modelos de aprendizado de máquina.
A importância da dimensão VC na classificação binária é reconhecida por instituições e organizações de pesquisa de destaque na área de inteligência artificial e aprendizado de máquina, como a Associação para o Avanço da Inteligência Artificial e Associação para a Maquinária de Computação. Essas organizações apoiam a pesquisa e a disseminação de conceitos fundamentais como a dimensão VC, que continuam a moldar as bases teóricas e aplicações práticas do aprendizado de máquina.
Shattering, Funções de Crescimento e Sua Importância
Os conceitos de shattering e funções de crescimento são centrais para entender a dimensão Vapnik–Chervonenkis (VC), uma medida fundamental na teoria do aprendizado estatístico. A dimensão VC, introduzida por Vladimir Vapnik e Alexey Chervonenkis, quantifica a capacidade de um conjunto de funções (classe de hipóteses) para se ajustar a dados, e é crucial para analisar a capacidade de generalização dos algoritmos de aprendizado.
Shattering refere-se à capacidade de uma classe de hipóteses de classificar perfeitamente todas as rotulagens possíveis de um conjunto finito de pontos. Formalmente, um conjunto de pontos é considerado “shattered” por uma classe de hipóteses se, para cada atribuição possível de rótulos binários aos pontos, existe uma função na classe que separa corretamente os pontos de acordo com esses rótulos. Por exemplo, no caso de classificadores lineares em duas dimensões, qualquer conjunto de três pontos não colineares pode ser “shattered”, mas não todos os conjuntos de quatro pontos podem ser.
A função de crescimento, também conhecida como coeficiente de shattering, mede o número máximo de rotulagens distintas (dicotomias) que uma classe de hipóteses pode realizar em qualquer conjunto de n pontos. Se a classe de hipóteses pode “shatter” todos os conjuntos de n pontos, a função de crescimento é igual a 2n. No entanto, conforme n aumenta, a maioria das classes de hipóteses atinge um ponto em que não pode mais “shatter” todas as rotulagens possíveis, e a função de crescimento aumenta de forma mais lenta. A dimensão VC é definida como o maior inteiro d tal que a função de crescimento é igual a 2d; em outras palavras, é o tamanho do maior conjunto que pode ser “shattered” pela classe de hipóteses.
Esses conceitos são significativos porque fornecem uma maneira rigorosa de analisar a complexidade e o poder expressivo dos modelos de aprendizado. Uma dimensão VC mais alta indica um modelo mais expressivo, capaz de se ajustar a padrões mais complexos, mas também em maior risco de overfitting. Por outro lado, uma baixa dimensão VC sugere capacidade limitada, o que pode levar a underfitting. A dimensão VC está diretamente ligada aos limites de generalização: ela ajuda a determinar quanto de dados de treinamento são necessários para garantir que o desempenho do modelo em dados não vistos esteja próximo ao seu desempenho no conjunto de treinamento. Essa relação é formalizada em teoremas como o teorema fundamental do aprendizado estatístico, que fundamenta grande parte da teoria moderna do aprendizado de máquina.
O estudo de shattering e funções de crescimento, e sua conexão com a dimensão VC, é fundamental no trabalho de organizações como a Associação para o Avanço da Inteligência Artificial e Instituto de Estatística Matemática, que promovem investigação e disseminação de avanços na teoria do aprendizado estatístico e suas aplicações.
Dimensão VC e Capacidade do Modelo: Implicações Práticas
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, fornecendo uma medida rigorosa da capacidade ou complexidade de um conjunto de funções (classe de hipóteses) que um modelo de aprendizado de máquina pode implementar. Em termos práticos, a dimensão VC quantifica o maior número de pontos que podem ser “shattered” (ou seja, corretamente classificados de todas as maneiras possíveis) pelo modelo. Essa medida é crucial para entender a relação entre a capacidade de um modelo de se ajustar aos dados de treinamento e sua capacidade de generalizar para dados não vistos.
Uma dimensão VC mais alta indica uma classe de modelos mais expressiva, capaz de representar padrões mais complexos. Por exemplo, um classificador linear em um espaço bidimensional tem uma dimensão VC de 3, o que significa que pode “shatter” qualquer conjunto de três pontos, mas não todos os conjuntos de quatro. Em contraste, modelos mais complexos, como redes neurais com muitos parâmetros, podem ter dimensões VC muito mais altas, refletindo sua maior capacidade de se ajustar a conjuntos de dados diversos.
As implicações práticas da dimensão VC são mais evidentes no contexto de overfitting e underfitting. Se a dimensão VC de um modelo for muito maior do que o número de amostras de treinamento, o modelo pode overfit – memorizar os dados de treinamento em vez de aprender padrões generalizáveis. Por outro lado, se a dimensão VC for muito baixa, o modelo pode sofrer underfitting, falhando em capturar a estrutura subjacente dos dados. Assim, selecionar um modelo com uma dimensão VC apropriada em relação ao tamanho do conjunto de dados é essencial para alcançar um bom desempenho de generalização.
A dimensão VC também fundamenta garantias teóricas na teoria do aprendizado, como o quadro de aprendizado Provavelmente Aproximadamente Correto (PAC). Ela fornece limites na quantidade de amostras de treinamento necessárias para garantir que o risco empírico (erro no conjunto de treinamento) esteja próximo do risco verdadeiro (erro esperado em novos dados). Esses resultados orientam os praticantes na estimativa da complexidade da amostra necessária para um aprendizado confiável, especialmente em aplicações críticas, como diagnóstico médico ou sistemas autônomos.
Na prática, embora a dimensão VC exata seja frequentemente difícil de calcular para modelos complexos, seu papel conceitual informa o design e a seleção de algoritmos. Técnicas de regularização, critérios de seleção de modelos e estratégias de validação cruzada são todas influenciadas pelos princípios subjacentes de controle de capacidade articulados pela dimensão VC. O conceito foi introduzido por Vladimir Vapnik e Alexey Chervonenkis, cujo trabalho lançou as bases para a teoria moderna do aprendizado estatístico e continua a influenciar pesquisa e aplicações em aprendizado de máquina (Instituto de Estatística Matemática).
Conexões com Overfitting e Limites de Generalização
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, influenciando diretamente nossa compreensão de overfitting e generalização em modelos de aprendizado de máquina. A dimensão VC quantifica a capacidade ou complexidade de um conjunto de funções (classe de hipóteses) medindo o maior conjunto de pontos que podem ser “shattered”—ou seja, corretamente classificados de todas as maneiras possíveis—pelas funções na classe. Essa medida é crucial para analisar quão bem um modelo treinado em um conjunto de dados finito irá se comportar em dados não vistos, uma propriedade conhecida como generalização.
Overfitting ocorre quando um modelo aprende não apenas os padrões subjacentes, mas também o ruído nos dados de treinamento, resultando em desempenho ruim em novos dados não vistos. A dimensão VC fornece uma estrutura teórica para entender e mitigar overfitting. Se a dimensão VC de uma classe de hipóteses for muito maior do que o número de amostras de treinamento, o modelo tem capacidade suficiente para ajustar o ruído aleatório, aumentando o risco de overfitting. Por outro lado, se a dimensão VC for muito baixa, o modelo pode sofrer underfitting, falhando em capturar a estrutura essencial dos dados.
A relação entre a dimensão VC e a generalização é formalizada através de limites de generalização. Esses limites, como aqueles derivados do trabalho fundamental de Vladimir Vapnik e Alexey Chervonenkis, afirmam que, com alta probabilidade, a diferença entre o risco empírico (erro no conjunto de treinamento) e o risco verdadeiro (erro esperado em novos dados) é pequena se o número de amostras de treinamento for suficientemente grande em relação à dimensão VC. Especificamente, o erro de generalização diminui à medida que o número de amostras aumenta, desde que a dimensão VC permaneça fixa. Essa percepção fundamenta o princípio de que modelos mais complexos (com maior dimensão VC) requerem mais dados para generalizar bem.
- A dimensão VC é central para a teoria da convergência uniforme, que garante que médias empíricas convergem para valores esperados uniformemente sobre todas as funções na classe de hipóteses. Essa propriedade é essencial para garantir que minimizar o erro no conjunto de treinamento leve a um baixo erro em dados não vistos.
- O conceito também é integral ao desenvolvimento de minimização de risco estrutural, uma estratégia que equilibra a complexidade do modelo e o erro de treinamento para alcançar uma generalização ótima, conforme formalizado na teoria das máquinas de vetor de suporte e outros algoritmos de aprendizado.
A importância da dimensão VC na compreensão do overfitting e da generalização é reconhecida por instituições de pesquisa de destaque e é fundamental no currículo da teoria do aprendizado estatístico, conforme delineado por organizações como o Instituto para Estudos Avançados e a Associação para o Avanço da Inteligência Artificial. Essas organizações contribuem para o desenvolvimento contínuo e disseminação de avanços teóricos em aprendizado de máquina.
Dimensão VC em Algoritmos de Aprendizado de Máquina do Mundo Real
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, fornecendo uma medida rigorosa da capacidade ou complexidade de um conjunto de funções (classe de hipóteses) que um algoritmo de aprendizado de máquina pode implementar. No aprendizado de máquina do mundo real, a dimensão VC desempenha um papel crucial na compreensão da capacidade de generalização dos algoritmos — quão bem um modelo treinado em uma amostra finita é esperado desempenhar em dados não vistos.
Em termos práticos, a dimensão VC ajuda a quantificar a relação entre a complexidade do modelo e o risco de overfitting. Por exemplo, um classificador linear em um espaço bidimensional (como um perceptron) tem uma dimensão VC de 3, o que significa que pode “shatter” qualquer conjunto de três pontos, mas não todos os conjuntos de quatro. Modelos mais complexos, como redes neurais, podem ter dimensões VC muito mais altas, refletindo sua capacidade de se ajustar a padrões mais intricados nos dados. No entanto, uma maior dimensão VC também aumenta o risco de overfitting, onde o modelo captura ruído em vez de estrutura subjacente.
A dimensão VC é particularmente relevante no contexto do quadro de aprendizado Provavelmente Aproximadamente Correto (PAC), que fornece garantias teóricas sobre o número de amostras de treinamento necessárias para alcançar um nível desejado de precisão e confiança. De acordo com a teoria, a complexidade da amostra — o número de exemplos necessários para o aprendizado — cresce com a dimensão VC da classe de hipóteses. Essa relação orienta os praticantes na seleção de classes de modelos apropriadas e estratégias de regularização para equilibrar expressividade e generalização.
Em aplicações do mundo real, a dimensão VC informa o design e a avaliação de algoritmos, como máquinas de vetor de suporte (SVMs), árvores de decisão e redes neurais. Por exemplo, as SVMs estão intimamente ligadas à teoria VC, já que seu princípio de maximização da margem pode ser interpretado como uma maneira de controlar a dimensão VC efetiva do classificador, melhorando assim o desempenho da generalização. Da mesma forma, técnicas de poda em árvores de decisão podem ser vistas como métodos para reduzir a dimensão VC e mitigar o overfitting.
Embora a dimensão VC exata de modelos complexos como redes neurais profundas seja frequentemente difícil de calcular, o conceito continua a ser influente na orientação da pesquisa e prática. Ele fundamenta o desenvolvimento de métodos de regularização, critérios de seleção de modelos e limites teóricos sobre o desempenho de aprendizado. A relevância duradoura da dimensão VC se reflete em seu papel fundamental no trabalho de organizações como a Associação para o Avanço da Inteligência Artificial e a Associação para a Maquinária de Computação, que promovem pesquisa na teoria do aprendizado de máquina e suas implicações práticas.
Limitações e Críticas à Dimensão VC
A dimensão Vapnik–Chervonenkis (VC) é um conceito fundamental na teoria do aprendizado estatístico, fornecendo uma medida da capacidade ou complexidade de um conjunto de funções (classe de hipóteses) em termos de sua capacidade de “shatter” pontos de dados. Apesar de sua importância teórica, a dimensão VC apresenta várias limitações notáveis e tem sido alvo de diversas críticas nas comunidades de aprendizado de máquina e estatística.
Uma limitação primária da dimensão VC é seu foco em cenários de pior caso. A dimensão VC quantifica o maior conjunto de pontos que podem ser “shattered” por uma classe de hipóteses, mas isso não reflete sempre o desempenho típico ou médio dos algoritmos de aprendizado em configurações práticas. Como resultado, a dimensão VC pode superestimar a verdadeira complexidade necessária para uma generalização bem-sucedida em dados do mundo real, onde as distribuições frequentemente estão longe do adversarial ou pior caso. Essa desconexão pode levar a limites excessivamente pessimistas na complexidade da amostra e no erro de generalização.
Outra crítica diz respeito à aplicabilidade da dimensão VC a modelos modernos de aprendizado de máquina, especialmente redes neurais profundas. Embora a dimensão VC esteja bem definida para classes de hipóteses simples, como classificadores lineares ou árvores de decisão, torna-se difícil calcular ou mesmo interpretar de forma significativa para modelos altamente parametrizados. Em muitos casos, redes profundas podem ter dimensões VC extremamente altas ou até mesmo infinitas, mas ainda assim generalizam bem na prática. Esse fenômeno, às vezes referido como o “paradoxo da generalização”, sugere que a dimensão VC não captura totalmente os fatores que regem a generalização em sistemas contemporâneos de aprendizado de máquina.
Além disso, a dimensão VC é inerentemente uma medida combinatória, ignorando a geometria e a estrutura da distribuição de dados. Ela não considera propriedades baseadas em margem, regularização ou outras técnicas algorítmicas que podem afetar significativamente a generalização. Medidas alternativas de complexidade, como complexidade de Rademacher ou números de cobertura, foram propostas para abordar algumas dessas deficiências, incorporando aspectos relacionados a dados ou geométricos.
Finalmente, a dimensão VC assume que os pontos de dados são independentes e identicamente distribuídos (i.i.d.), uma suposição que pode não ser válida em muitas aplicações do mundo real, como análise de séries temporais ou tarefas de predição estruturada. Isso limita ainda mais a aplicabilidade direta da teoria baseada na dimensão VC em certos domínios.
Apesar dessas limitações, a dimensão VC continua a ser um pilar da teoria do aprendizado, fornecendo insights valiosos sobre os limites fundamentais da aprendibilidade. Pesquisas contínuas por organizações como a Associação para o Avanço da Inteligência Artificial e o Instituto de Estatística Matemática continuam a explorar extensões e alternativas à estrutura VC, visando alinhar melhor garantias teóricas com observações empíricas em aprendizado de máquina moderno.
Direções Futuras e Problemas Abertos na Teoria VC
A dimensão Vapnik–Chervonenkis (VC) continua a ser um pilar da teoria do aprendizado estatístico, fornecendo uma medida rigorosa da capacidade de classes de hipóteses e sua capacidade de generalização a partir de amostras finitas. Apesar de seu papel fundamental, várias direções futuras e problemas abertos continuam a impulsionar a pesquisa na teoria VC, refletindo tanto desafios teóricos quanto demandas práticas no aprendizado de máquina moderno.
Uma direção proeminente é a extensão da teoria VC para domínios de dados mais complexos e estruturados. A análise da dimensão VC tradicional é bem adequada para classificação binária e espaços de hipóteses simples, mas aplicações modernas muitas vezes envolvem saídas multiclasses, estruturadas ou dados com dependências intrincadas. Desenvolver noções generalizadas de dimensão VC que possam capturar a complexidade de redes neurais profundas, arquiteturas recorrentes e outros modelos avançados continua a ser um desafio em aberto. Isso inclui entender a capacidade efetiva desses modelos e como ela se relaciona ao seu desempenho empírico e capacidade de generalização.
Outra área ativa de pesquisa é o aspecto computacional da dimensão VC. Enquanto a dimensão VC fornece garantias teóricas, calcular ou mesmo aproximar a dimensão VC para classes de hipóteses arbitrárias é frequentemente intratável. Algoritmos eficientes para estimar a dimensão VC, especialmente para modelos em grande escala ou alta dimensão, são altamente desejados. Isso tem implicações para seleção de modelos, regularização e o design de algoritmos de aprendizado que podem controlar adaptativamente a complexidade do modelo.
A relação entre a dimensão VC e outras medidas de complexidade, como complexidade de Rademacher, números de cobertura e estabilidade algorítmica, também apresenta um terreno fértil para exploração. À medida que os modelos de aprendizado de máquina se tornam mais sofisticados, entender como essas diferentes medidas interagem e quais são mais preditivas da generalização na prática é um problema aberto chave. Isso é particularmente relevante no contexto de modelos superparametrizados, onde a teoria VC clássica pode não explicar totalmente os fenômenos de generalização observados.
Além disso, o advento de preocupações com privacidade e justiça introduz novas dimensões à teoria VC. Pesquisadores estão investigando como restrições, como privacidade diferencial ou requisitos de justiça, impactam a dimensão VC e, consequentemente, a aprendibilidade das classes de hipóteses sob essas restrições. Essa intersecção da teoria VC com considerações éticas e legais provavelmente crescerá em importância à medida que sistemas de aprendizado de máquina são cada vez mais implantados em domínios sensíveis.
Finalmente, o desenvolvimento contínuo da computação quântica e suas potenciais aplicações em aprendizado de máquina levantam questões sobre a dimensão VC em espaços de hipóteses quânticas. Compreender como os recursos quânticos afetam a capacidade e a generalização de algoritmos de aprendizado é uma área emergente de investigação teórica.
À medida que o campo evolui, organizações como a Associação para o Avanço da Inteligência Artificial e o Instituto de Estatística Matemática continuam a apoiar a pesquisa e a disseminação de avanços na teoria VC, garantindo que questões fundamentais permaneçam na vanguarda da pesquisa em aprendizado de máquina.
Fontes & Referências
- Instituto para Estudos Avançados
- Sociedade Americana de Matemática
- Associação para a Maquinária de Computação