Demystifying the Vapnik–Chervonenkis Dimension: The Key to Understanding Model Complexity and Generalization in Machine Learning. Discover How VC Dimension Shapes the Boundaries of What Algorithms Can Learn.
- Introduction to Vapnik–Chervonenkis Dimension
- Historical Origins and Theoretical Foundations
- Formal Definition and Mathematical Framework
- VC Dimension in Binary Classification
- Shattering, Growth Functions, and Their Significance
- VC Dimension and Model Capacity: Practical Implications
- Connections to Overfitting and Generalization Bounds
- VC Dimension in Real-World Machine Learning Algorithms
- Limitations and Critiques of VC Dimension
- Future Directions and Open Problems in VC Theory
- Sources & References
Introduction to Vapnik–Chervonenkis Dimension
The Vapnik–Chervonenkis dimension (VC dimension) is a fundamental concept in statistical learning theory, introduced by Vladimir Vapnik and Alexey Chervonenkis in the early 1970s. It provides a rigorous mathematical framework for quantifying the capacity or complexity of a set of functions (hypothesis class) in terms of its ability to classify data points. The VC dimension is defined as the largest number of points that can be shattered (i.e., correctly classified in all possible ways) by the hypothesis class. This concept is central to understanding the generalization ability of learning algorithms, as it connects the expressiveness of a model to its risk of overfitting.
In more formal terms, if a hypothesis class can shatter a set of n points, but cannot shatter any set of n+1 points, then its VC dimension is n. For example, the class of linear classifiers in two-dimensional space has a VC dimension of 3, meaning it can shatter any set of three points, but not all sets of four points. The VC dimension thus serves as a measure of the richness of a hypothesis class, independent of the specific data distribution.
The importance of the VC dimension lies in its role in providing theoretical guarantees for machine learning algorithms. It is a key component in the derivation of bounds on the generalization error, which is the difference between the error on the training data and the expected error on unseen data. The celebrated VC inequality, for instance, relates the VC dimension to the probability that the empirical risk (training error) deviates from the true risk (generalization error). This relationship underpins the principle of structural risk minimization, a cornerstone of modern statistical learning theory, which seeks to balance model complexity and training error to achieve optimal generalization.
The concept of VC dimension has been widely adopted in the analysis of various learning algorithms, including support vector machines, neural networks, and decision trees. It is also foundational in the development of the Probably Approximately Correct (PAC) learning framework, which formalizes the conditions under which a learning algorithm can be expected to perform well. The theoretical underpinnings provided by the VC dimension have been instrumental in advancing the field of machine learning and are recognized by leading research institutions such as Institute for Advanced Study and Association for the Advancement of Artificial Intelligence.
Historical Origins and Theoretical Foundations
The Vapnik–Chervonenkis (VC) dimension is a foundational concept in statistical learning theory, introduced in the early 1970s by Vladimir Vapnik and Alexey Chervonenkis. Their pioneering work emerged from the Institute of Control Sciences of the Russian Academy of Sciences, where they sought to formalize the principles underlying pattern recognition and machine learning. The VC dimension provides a rigorous mathematical framework for quantifying the capacity of a set of functions (hypothesis class) to fit data, which is crucial for understanding the generalization ability of learning algorithms.
At its core, the VC dimension measures the largest number of points that can be shattered (i.e., correctly classified in all possible ways) by a hypothesis class. If a class of functions can shatter a set of size d but not d+1, its VC dimension is d. This concept allows researchers to analyze the trade-off between model complexity and the risk of overfitting, a central concern in machine learning. The introduction of the VC dimension marked a significant advance over earlier, less formal approaches to learning theory, providing a bridge between empirical performance and theoretical guarantees.
The theoretical foundations of the VC dimension are closely linked to the development of the Probably Approximately Correct (PAC) learning framework, which formalizes the conditions under which a learning algorithm can be expected to perform well on unseen data. The VC dimension serves as a key parameter in theorems that bound the generalization error of classifiers, establishing that a finite VC dimension is necessary for learnability in the PAC sense. This insight has had a profound impact on the design and analysis of algorithms in fields ranging from computer vision to natural language processing.
Vapnik and Chervonenkis’s work laid the groundwork for the development of support vector machines and other kernel-based methods, which rely on the principles of capacity control and structural risk minimization. Their contributions have been recognized by leading scientific organizations, and the VC dimension remains a central topic in the curriculum of advanced machine learning and statistics courses worldwide. The American Mathematical Society and the Association for the Advancement of Artificial Intelligence are among the organizations that have highlighted the significance of these theoretical advances in their publications and conferences.
Formal Definition and Mathematical Framework
The Vapnik–Chervonenkis (VC) dimension is a fundamental concept in statistical learning theory, providing a rigorous measure of the capacity or complexity of a set of functions (hypothesis class) in terms of its ability to classify data points. Formally, the VC dimension is defined for a class of indicator functions (or sets) as the largest number of points that can be shattered by the class. To “shatter” a set of points means that, for every possible labeling of those points, there exists a function in the class that correctly assigns those labels.
Let H be a hypothesis class of binary-valued functions mapping from an input space X to {0,1}. A set of points S = {x₁, x₂, …, xₙ} is said to be shattered by H if, for every possible subset A of S, there exists a function h ∈ H such that h(x) = 1 if and only if x ∈ A. The VC dimension of H, denoted VC(H), is the maximum cardinality n such that there exists a set of n points in X shattered by H. If arbitrarily large finite sets can be shattered, the VC dimension is infinite.
Mathematically, the VC dimension provides a bridge between the expressiveness of a hypothesis class and its generalization ability. A higher VC dimension indicates a more expressive class, capable of fitting more complex patterns, but also at greater risk of overfitting. Conversely, a lower VC dimension suggests limited expressiveness and potentially better generalization, but possibly at the cost of underfitting. The VC dimension is central to the derivation of generalization bounds, such as those formalized in the fundamental theorems of statistical learning theory, which relate the VC dimension to the sample complexity required for learning with a given accuracy and confidence.
The concept was introduced by Vladimir Vapnik and Alexey Chervonenkis in the 1970s, and it underpins the theoretical analysis of learning algorithms, including support vector machines and empirical risk minimization frameworks. The VC dimension is widely recognized and utilized in the field of machine learning and is discussed in detail by organizations such as the Institute of Mathematical Statistics and the Association for the Advancement of Artificial Intelligence, both of which are leading authorities in statistics and artificial intelligence research, respectively.
VC Dimension in Binary Classification
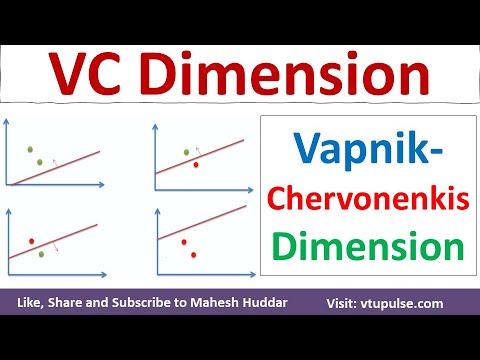
The Vapnik–Chervonenkis (VC) dimension is a fundamental concept in statistical learning theory, particularly relevant to the analysis of binary classification models. Introduced by Vladimir Vapnik and Alexey Chervonenkis in the early 1970s, the VC dimension quantifies the capacity or complexity of a set of functions (hypothesis class) by measuring its ability to shatter finite sets of data points. In the context of binary classification, “shattering” refers to the ability of a classifier to correctly label all possible assignments of binary labels (0 or 1) to a given set of points.
Formally, the VC dimension of a hypothesis class is the largest number of points that can be shattered by that class. For example, consider the class of linear classifiers (perceptrons) in a two-dimensional space. This class can shatter any set of three points in general position, but not all sets of four points. Therefore, the VC dimension of linear classifiers in two dimensions is three. The VC dimension provides a measure of the expressiveness of a model: a higher VC dimension indicates a more flexible model that can fit more complex patterns, but also increases the risk of overfitting.
In binary classification, the VC dimension plays a crucial role in understanding the trade-off between model complexity and generalization. According to the theory, if the VC dimension is too high relative to the number of training samples, the model may fit the training data perfectly but fail to generalize to unseen data. Conversely, a model with a low VC dimension may underfit, failing to capture important patterns in the data. The VC dimension thus provides theoretical guarantees on the generalization error, as formalized in the VC inequality and related bounds.
The concept of VC dimension is central to the development of learning algorithms and the analysis of their performance. It underpins the Probably Approximately Correct (PAC) learning framework, which characterizes the conditions under which a learning algorithm can achieve low generalization error with high probability. The VC dimension is also used in the design and analysis of support vector machines (SVMs), a widely used class of binary classifiers, as well as in the study of neural networks and other machine learning models.
The importance of the VC dimension in binary classification is recognized by leading research institutions and organizations in the field of artificial intelligence and machine learning, such as Association for the Advancement of Artificial Intelligence and Association for Computing Machinery. These organizations support research and dissemination of foundational concepts like the VC dimension, which continue to shape the theoretical underpinnings and practical applications of machine learning.
Shattering, Growth Functions, and Their Significance
The concepts of shattering and growth functions are central to understanding the Vapnik–Chervonenkis (VC) dimension, a foundational measure in statistical learning theory. The VC dimension, introduced by Vladimir Vapnik and Alexey Chervonenkis, quantifies the capacity of a set of functions (hypothesis class) to fit data, and is crucial for analyzing the generalization ability of learning algorithms.
Shattering refers to the ability of a hypothesis class to perfectly classify all possible labelings of a finite set of points. Formally, a set of points is said to be shattered by a hypothesis class if, for every possible assignment of binary labels to the points, there exists a function in the class that correctly separates the points according to those labels. For example, in the case of linear classifiers in two dimensions, any set of three non-collinear points can be shattered, but not all sets of four points can be.
The growth function, also known as the shatter coefficient, measures the maximum number of distinct labelings (dichotomies) that a hypothesis class can realize on any set of n points. If the hypothesis class can shatter every set of n points, the growth function equals 2n. However, as n increases, most hypothesis classes reach a point where they can no longer shatter all possible labelings, and the growth function increases more slowly. The VC dimension is defined as the largest integer d such that the growth function equals 2d; in other words, it is the size of the largest set that can be shattered by the hypothesis class.
These concepts are significant because they provide a rigorous way to analyze the complexity and expressive power of learning models. A higher VC dimension indicates a more expressive model, capable of fitting more complex patterns, but also at greater risk of overfitting. Conversely, a low VC dimension suggests limited capacity, which may lead to underfitting. The VC dimension is directly linked to generalization bounds: it helps determine how much training data is needed to ensure that the model’s performance on unseen data will be close to its performance on the training set. This relationship is formalized in theorems such as the fundamental theorem of statistical learning, which underpins much of modern machine learning theory.
The study of shattering and growth functions, and their connection to the VC dimension, is foundational in the work of organizations such as Association for the Advancement of Artificial Intelligence and Institute of Mathematical Statistics, which promote research and dissemination of advances in statistical learning theory and its applications.
VC Dimension and Model Capacity: Practical Implications
The Vapnik–Chervonenkis (VC) dimension is a foundational concept in statistical learning theory, providing a rigorous measure of the capacity or complexity of a set of functions (hypothesis class) that a machine learning model can implement. In practical terms, the VC dimension quantifies the largest number of points that can be shattered (i.e., correctly classified in all possible ways) by the model. This measure is crucial for understanding the trade-off between a model’s ability to fit training data and its ability to generalize to unseen data.
A higher VC dimension indicates a more expressive model class, capable of representing more complex patterns. For example, a linear classifier in a two-dimensional space has a VC dimension of 3, meaning it can shatter any set of three points but not all sets of four. In contrast, more complex models, such as neural networks with many parameters, can have much higher VC dimensions, reflecting their greater capacity to fit diverse datasets.
The practical implications of the VC dimension are most evident in the context of overfitting and underfitting. If a model’s VC dimension is much larger than the number of training samples, the model may overfit—memorizing the training data rather than learning generalizable patterns. Conversely, if the VC dimension is too low, the model may underfit, failing to capture the underlying structure of the data. Thus, selecting a model with an appropriate VC dimension relative to the dataset size is essential for achieving good generalization performance.
The VC dimension also underpins theoretical guarantees in learning theory, such as the Probably Approximately Correct (PAC) learning framework. It provides bounds on the number of training samples required to ensure that the empirical risk (error on the training set) is close to the true risk (expected error on new data). These results guide practitioners in estimating the sample complexity needed for reliable learning, especially in high-stakes applications like medical diagnosis or autonomous systems.
In practice, while the exact VC dimension is often difficult to compute for complex models, its conceptual role informs the design and selection of algorithms. Regularization techniques, model selection criteria, and cross-validation strategies are all influenced by the underlying principles of capacity control articulated by the VC dimension. The concept was introduced by Vladimir Vapnik and Alexey Chervonenkis, whose work laid the foundation for modern statistical learning theory and continues to influence research and applications in machine learning (Institute of Mathematical Statistics).
Connections to Overfitting and Generalization Bounds
The Vapnik–Chervonenkis (VC) dimension is a foundational concept in statistical learning theory, directly influencing our understanding of overfitting and generalization in machine learning models. The VC dimension quantifies the capacity or complexity of a set of functions (hypothesis class) by measuring the largest set of points that can be shattered—i.e., correctly classified in all possible ways—by the functions in the class. This measure is crucial for analyzing how well a model trained on a finite dataset will perform on unseen data, a property known as generalization.
Overfitting occurs when a model learns not only the underlying patterns but also the noise in the training data, resulting in poor performance on new, unseen data. The VC dimension provides a theoretical framework to understand and mitigate overfitting. If the VC dimension of a hypothesis class is much larger than the number of training samples, the model has enough capacity to fit random noise, increasing the risk of overfitting. Conversely, if the VC dimension is too low, the model may underfit, failing to capture the essential structure of the data.
The relationship between VC dimension and generalization is formalized through generalization bounds. These bounds, such as those derived from the fundamental work of Vladimir Vapnik and Alexey Chervonenkis, state that with high probability, the difference between the empirical risk (error on the training set) and the true risk (expected error on new data) is small if the number of training samples is sufficiently large relative to the VC dimension. Specifically, the generalization error decreases as the number of samples increases, provided the VC dimension remains fixed. This insight underpins the principle that more complex models (with higher VC dimension) require more data to generalize well.
- The VC dimension is central to the theory of uniform convergence, which ensures that empirical averages converge to expected values uniformly over all functions in the hypothesis class. This property is essential for guaranteeing that minimizing error on the training set leads to low error on unseen data.
- The concept is also integral to the development of structural risk minimization, a strategy that balances model complexity and training error to achieve optimal generalization, as formalized in the theory of support vector machines and other learning algorithms.
The importance of the VC dimension in understanding overfitting and generalization is recognized by leading research institutions and is foundational in the curriculum of statistical learning theory, as outlined by organizations such as the Institute for Advanced Study and the Association for the Advancement of Artificial Intelligence. These organizations contribute to the ongoing development and dissemination of theoretical advances in machine learning.
VC Dimension in Real-World Machine Learning Algorithms
The Vapnik–Chervonenkis (VC) dimension is a foundational concept in statistical learning theory, providing a rigorous measure of the capacity or complexity of a set of functions (hypothesis class) that a machine learning algorithm can implement. In real-world machine learning, the VC dimension plays a crucial role in understanding the generalization ability of algorithms—how well a model trained on a finite sample is expected to perform on unseen data.
In practical terms, the VC dimension helps quantify the trade-off between model complexity and the risk of overfitting. For example, a linear classifier in a two-dimensional space (such as a perceptron) has a VC dimension of 3, meaning it can shatter any set of three points but not all sets of four. More complex models, such as neural networks, can have much higher VC dimensions, reflecting their ability to fit more intricate patterns in data. However, a higher VC dimension also increases the risk of overfitting, where the model captures noise rather than underlying structure.
The VC dimension is particularly relevant in the context of the Probably Approximately Correct (PAC) learning framework, which provides theoretical guarantees on the number of training samples required to achieve a desired level of accuracy and confidence. According to the theory, the sample complexity—the number of examples needed for learning—grows with the VC dimension of the hypothesis class. This relationship guides practitioners in selecting appropriate model classes and regularization strategies to balance expressiveness and generalization.
In real-world applications, the VC dimension informs the design and evaluation of algorithms such as support vector machines (SVMs), decision trees, and neural networks. For instance, SVMs are closely linked to VC theory, as their margin maximization principle can be interpreted as a way to control the effective VC dimension of the classifier, thereby improving generalization performance. Similarly, pruning techniques in decision trees can be viewed as methods to reduce the VC dimension and mitigate overfitting.
While the exact VC dimension of complex models like deep neural networks is often difficult to compute, the concept remains influential in guiding research and practice. It underpins the development of regularization methods, model selection criteria, and theoretical bounds on learning performance. The enduring relevance of the VC dimension is reflected in its foundational role in the work of organizations such as the Association for the Advancement of Artificial Intelligence and the Association for Computing Machinery, which promote research in machine learning theory and its practical implications.
Limitations and Critiques of VC Dimension
The Vapnik–Chervonenkis (VC) dimension is a foundational concept in statistical learning theory, providing a measure of the capacity or complexity of a set of functions (hypothesis class) in terms of its ability to shatter data points. Despite its theoretical significance, the VC dimension has several notable limitations and has been subject to various critiques within the machine learning and statistical communities.
One primary limitation of the VC dimension is its focus on worst-case scenarios. The VC dimension quantifies the largest set of points that can be shattered by a hypothesis class, but this does not always reflect the typical or average-case performance of learning algorithms in practical settings. As a result, the VC dimension may overestimate the true complexity required for successful generalization in real-world data, where distributions are often far from adversarial or worst-case. This disconnect can lead to overly pessimistic bounds on sample complexity and generalization error.
Another critique concerns the applicability of the VC dimension to modern machine learning models, particularly deep neural networks. While the VC dimension is well-defined for simple hypothesis classes such as linear classifiers or decision trees, it becomes difficult to compute or even meaningfully interpret for highly parameterized models. In many cases, deep networks can have extremely high or even infinite VC dimensions, yet still generalize well in practice. This phenomenon, sometimes referred to as the “generalization paradox,” suggests that the VC dimension does not fully capture the factors that govern generalization in contemporary machine learning systems.
Additionally, the VC dimension is inherently a combinatorial measure, ignoring the geometry and structure of the data distribution. It does not account for margin-based properties, regularization, or other algorithmic techniques that can significantly affect generalization. Alternative complexity measures, such as Rademacher complexity or covering numbers, have been proposed to address some of these shortcomings by incorporating data-dependent or geometric aspects.
Finally, the VC dimension assumes that data points are independent and identically distributed (i.i.d.), an assumption that may not hold in many real-world applications, such as time series analysis or structured prediction tasks. This further limits the direct applicability of VC-based theory in certain domains.
Despite these limitations, the VC dimension remains a cornerstone of learning theory, providing valuable insights into the fundamental limits of learnability. Ongoing research by organizations such as the Association for the Advancement of Artificial Intelligence and the Institute of Mathematical Statistics continues to explore extensions and alternatives to the VC framework, aiming to better align theoretical guarantees with empirical observations in modern machine learning.
Future Directions and Open Problems in VC Theory
The Vapnik–Chervonenkis (VC) dimension remains a cornerstone of statistical learning theory, providing a rigorous measure of the capacity of hypothesis classes and their ability to generalize from finite samples. Despite its foundational role, several future directions and open problems continue to drive research in VC theory, reflecting both theoretical challenges and practical demands in modern machine learning.
One prominent direction is the extension of VC theory to more complex and structured data domains. Traditional VC dimension analysis is well-suited for binary classification and simple hypothesis spaces, but modern applications often involve multi-class, structured outputs, or data with intricate dependencies. Developing generalized notions of VC dimension that can capture the complexity of deep neural networks, recurrent architectures, and other advanced models remains an open challenge. This includes understanding the effective capacity of these models and how it relates to their empirical performance and generalization ability.
Another active area of research is the computational aspect of VC dimension. While the VC dimension provides theoretical guarantees, computing or even approximating the VC dimension for arbitrary hypothesis classes is often intractable. Efficient algorithms for estimating the VC dimension, especially for large-scale or high-dimensional models, are highly sought after. This has implications for model selection, regularization, and the design of learning algorithms that can adaptively control model complexity.
The relationship between VC dimension and other complexity measures, such as Rademacher complexity, covering numbers, and algorithmic stability, also presents fertile ground for exploration. As machine learning models become more sophisticated, understanding how these different measures interact and which are most predictive of generalization in practice is a key open problem. This is particularly relevant in the context of overparameterized models, where classical VC theory may not fully explain observed generalization phenomena.
Furthermore, the advent of data privacy and fairness concerns introduces new dimensions to VC theory. Researchers are investigating how constraints such as differential privacy or fairness requirements impact the VC dimension and, consequently, the learnability of hypothesis classes under these constraints. This intersection of VC theory with ethical and legal considerations is likely to grow in importance as machine learning systems are increasingly deployed in sensitive domains.
Finally, the ongoing development of quantum computing and its potential applications in machine learning raises questions about the VC dimension in quantum hypothesis spaces. Understanding how quantum resources affect the capacity and generalization of learning algorithms is an emerging area of theoretical inquiry.
As the field evolves, organizations such as the Association for the Advancement of Artificial Intelligence and the Institute of Mathematical Statistics continue to support research and dissemination of advances in VC theory, ensuring that foundational questions remain at the forefront of machine learning research.
Sources & References